Text-image Synthesis
DDPM
[1] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in NeurIPS, 2020.

Guided Diffusion
[2] P.DhariwalandA.Nichol, “Diffusion models beat gans on image synthesis,” in NeurIPS, 2021.

Latent Diffusion Model
[3] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022.
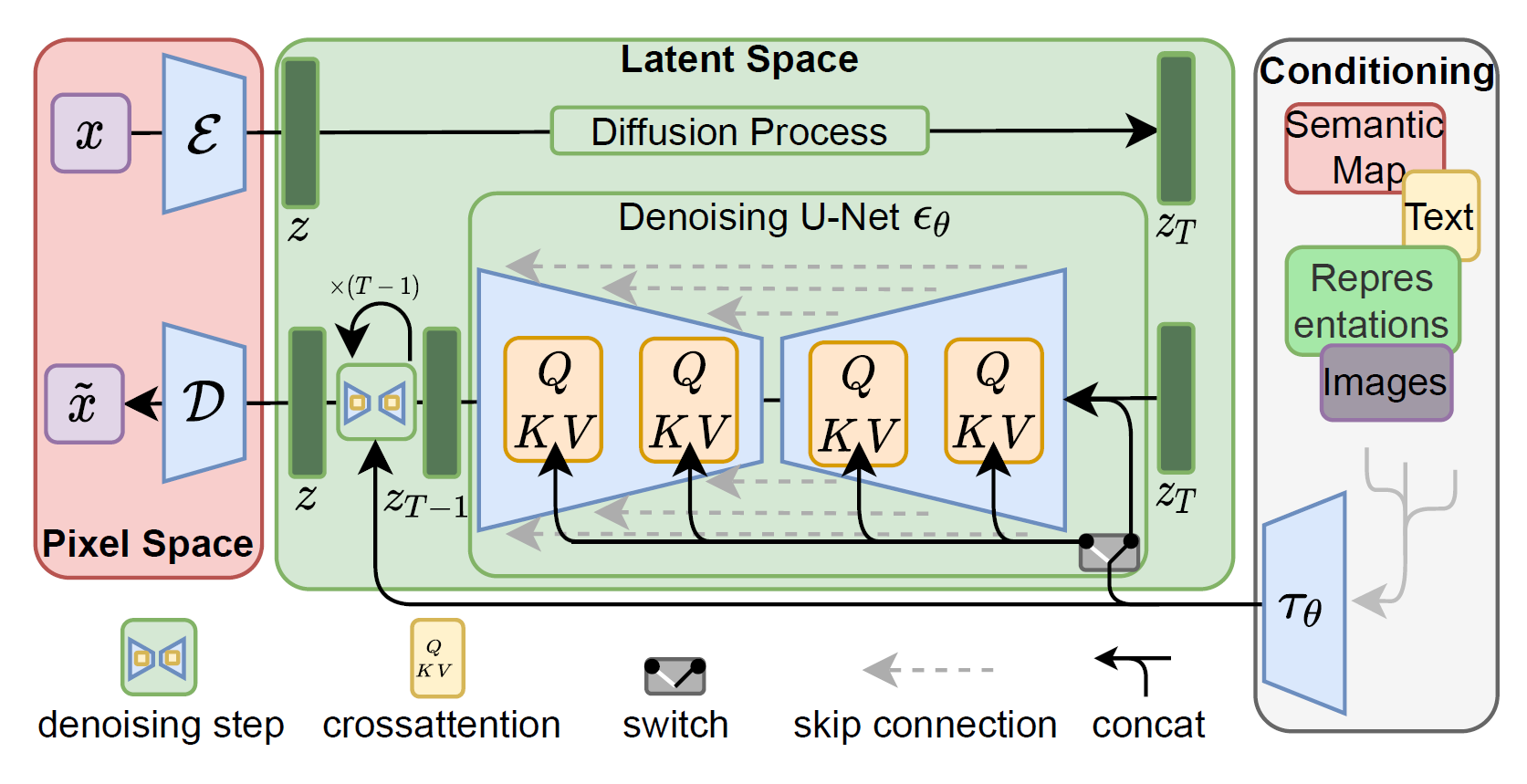
[论文阅读] High-Resolution Image Synthesis with Latent Diffusion Models - Chunleiii - 博客园
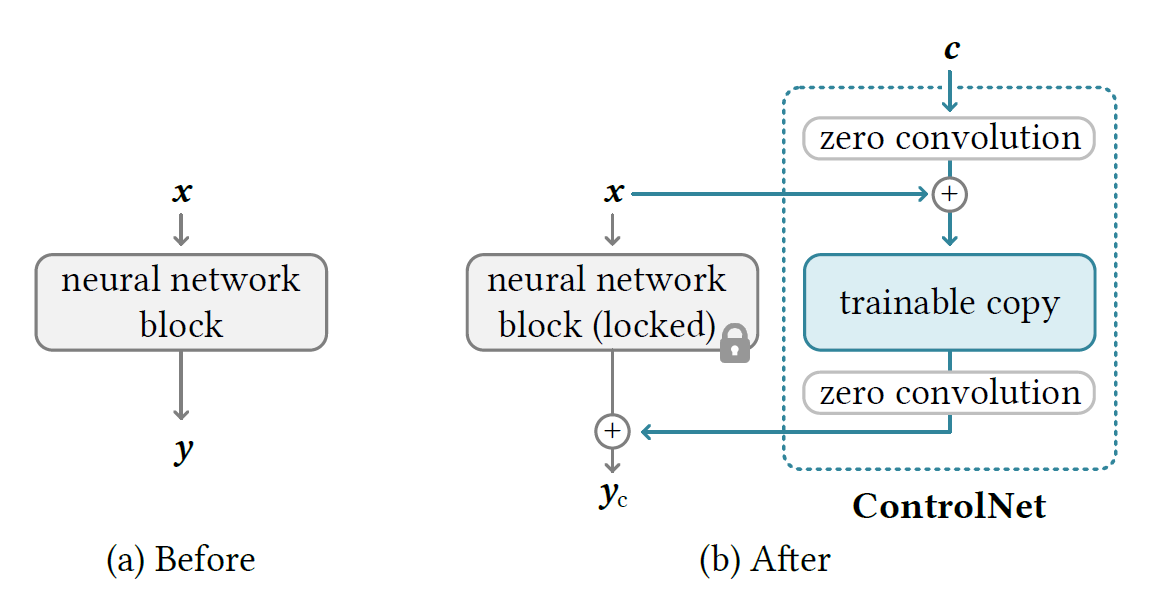
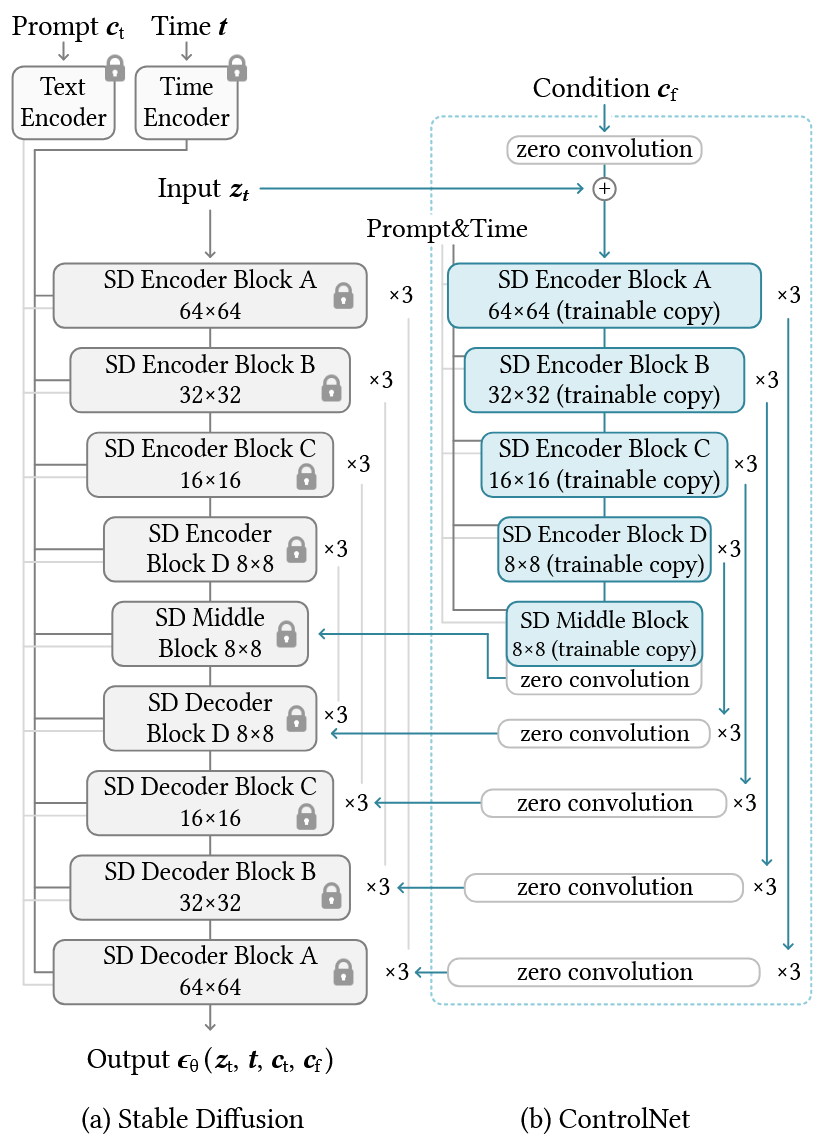
ControlNet
[4] L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” in ICCV, 2023.
Dreambooth
[5] N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation,” in CVPR, 2023.
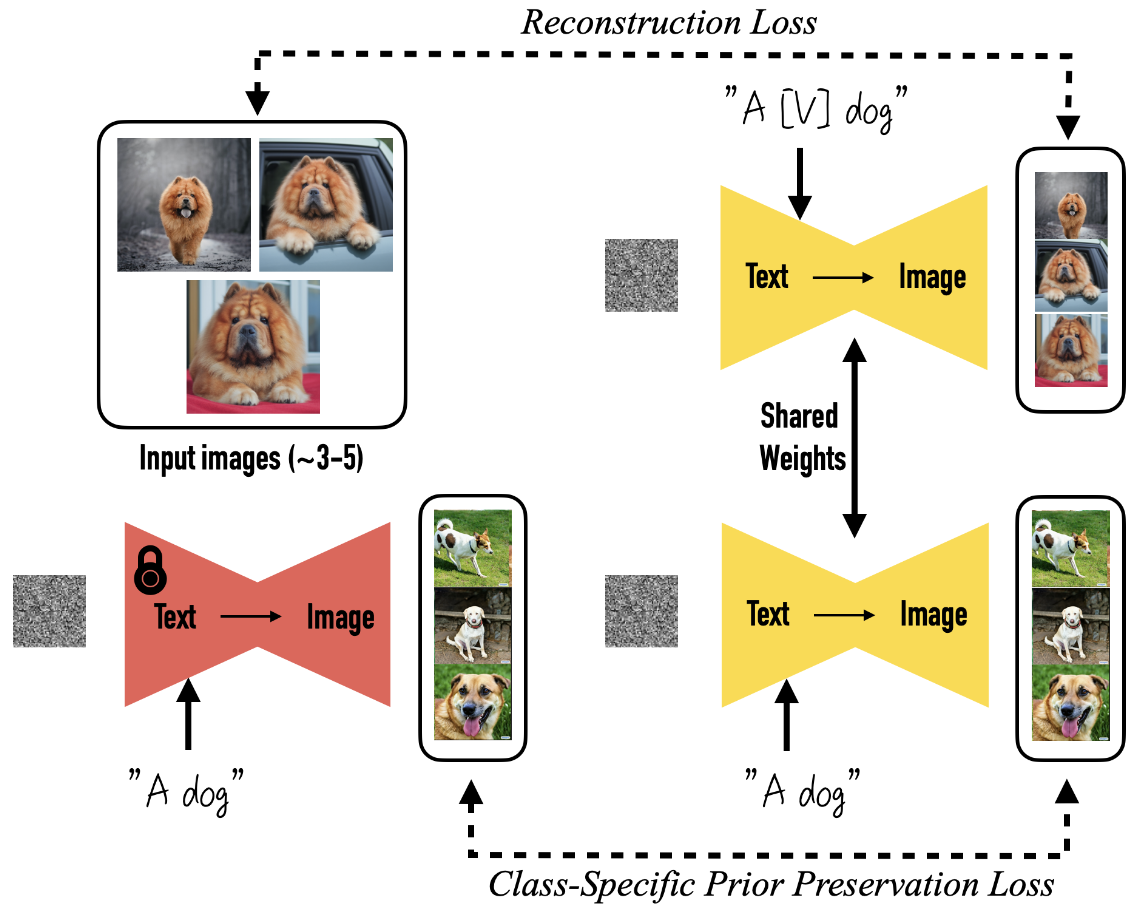
- 目标是什么?
让通用的
“文字生成图片” 模型学会认识你提供的特定东西(比如你家的狗),并能用新造的词(比如 “一个 [小 V] 狗”)来生成它在各种场景下的新图片,同时保持它独特的样子。 - 怎么做?
- 给你想教给模型的特定东西(比如你的狗)拍几张照片(大约
3-5 张)。 - 给模型看这些照片,同时配上文字描述。这个描述用一个特殊代号(如
[V])+ 这个东西的种类名(如 “狗”) 组成,比如 “一个 [V] 狗”。 - 这样微调模型时,模型就能:
- 利用它原本就懂
“狗” 是什么样子的知识(先验知识)。 - 把你这个特定的狗和那个特殊代号
[V] 牢牢绑定起来。
- 利用它原本就懂
- 给你想教给模型的特定东西(比如你的狗)拍几张照片(大约
- 防止模型忘本:
- 有个问题是,模型可能会把
“狗” 这个词只理解成你这条特定的狗,忘了其他狗长啥样(这叫 “语言漂移”)。 - 为了解决这个问题,他们发明了一个
“防遗忘训练法”: - 这个方法利用模型本身对
“狗” 这个种类的知识(比如知道狗有很多不同样子)。 - 在训练过程中,鼓励模型在看到单纯
“狗” 这个词时,仍然能生成各种各样不同的狗(而不是只生成你家那条狗)。这样就能保护模型对 “狗” 这个类别的理解。
- 这个方法利用模型本身对
- 有个问题是,模型可能会把
- 效果:
- 训练完成后,只要在文字描述里用那个特殊代号(如
“[V] 狗”),就能指挥模型生成你家那条狗在各种新场景、摆不同姿势、甚至变成艺术风格的照片了!就像放进一个 “魔法照相亭”。
- 训练完成后,只要在文字描述里用那个特殊代号(如
- 他们还做了这些:
- 尝试了各种文字生成图片的新玩法(给东西换背景、改属性、做艺术效果等)。
- 通过实验证明了他们方法里每个部分(特别是那个
“防遗忘训练法”)都很重要。 - 和其他方法做了对比实验。
- 请人实际测试,证明他们生成的图片里,东西的样子和文字描述的要求都更准确。
总结核心(完全对应原文): Dreambooth
教通用文生图模型认识你的特定东西(用几张照片),并绑定一个新词(特殊代号
流匹配
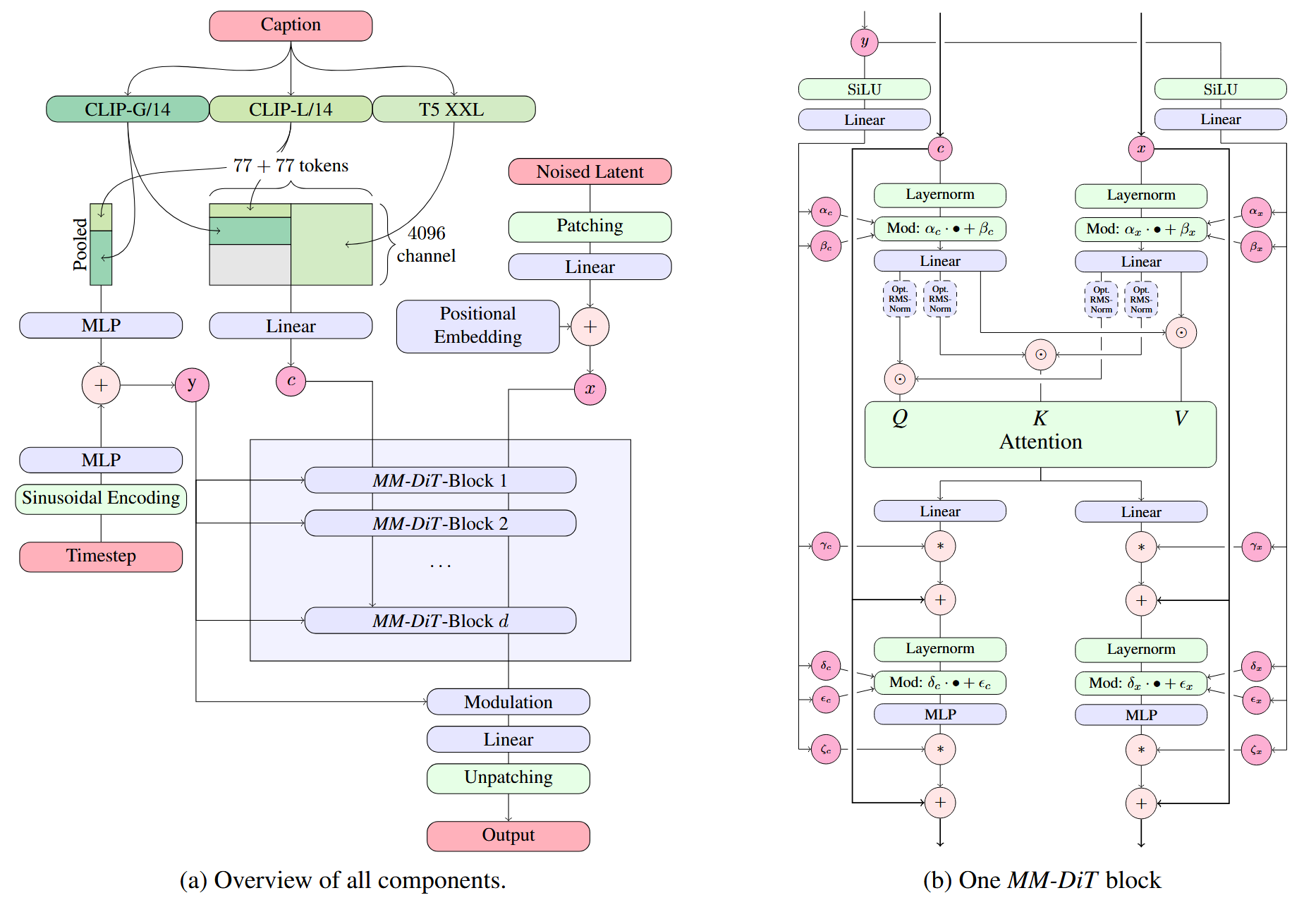
Multimodal Diffusion Backbone
[1] P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Muller, H. Saini, ¨ Y. Levi, D. Lorenz, A. Sauer, F. Boesel et al., “Scaling rectified flow transformers for high-resolution image synthesis,” in ICML, 2024.
Flow Matching
[2] Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., and Le, M. “Flow matching for generative modeling,”in ICLR 2023.
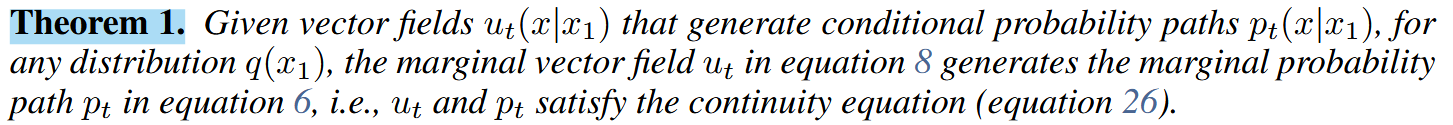
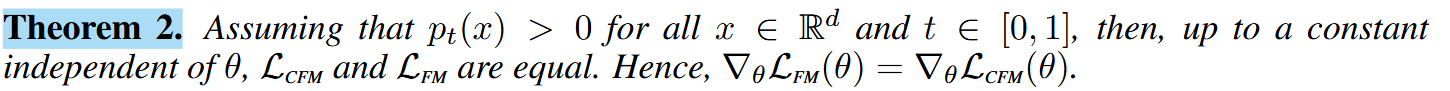

1. 为什么流匹配方法比传统的得分匹配方法更稳定?
得分匹配方法需要估计数据的概率密度对数的梯度,即得分函数,这在高维数据上可能具有较高的方差,导致训练不稳定。流匹配方法直接回归矢量场,避免了高方差的估计,同时通过条件流匹配,将训练过程分解为更简单的条件问题,提高了训练的稳定性。
2. 为什么最优传输路径能够提高采样效率?
最优传输路径中的样本以直线轨迹从初始分布移动到目标分布,路径更为直接,且速度恒定。这意味着采样过程可以使用更大的步长,减少步数,同时仍能保持较高的生成质量。因此,最优传输路径在采样效率上具有优势。
3. 流匹配方法是否适用于其他类型的数据?
虽然本文的实验主要集中在图像数据上,但流匹配方法本质上是通用的。由于它仅依赖于构建合适的条件概率路径和矢量场,因此可以适用于其他类型的数据,如文本、音频等,只要能够定义合适的概率路径。
4. 流匹配方法是否存在局限性?在什么情况下可能不起作用?
流匹配方法的效果取决于条件概率路径和条件矢量场的选择。如果条件概率路径无法有效地逼近数据分布,或者条件矢量场难以学习到真实的流,那么模型的性能可能会受到限制。此外,对于高维、复杂的数据分布,构建合适的概率路径和矢量场可能会更加困难,需要进一步的研究。
5. CNF
连续归一化流(Continuous Normalizing Flows, CNFs)和归一化流(Normalizing Flows, NFs)都是用于概率分布变换的技术。
归一化流(NF):
- 归一化流使用一系列可逆的、参数化的变换来将一个简单的分布(如高斯分布)变换为目标复杂分布。
- 这些变换通常是通过神经网络实现的,并且每个变换都是离散的。
连续归一化流(CNF):
- CNF
将这种变换的过程视为一个连续的系统,通过常微分方程(ODE)定义。 - 变换不再是离散的一步一步,而是一个连续的时间演化过程。
6. 什么是最优传输(Optimal Transport,OT)路径?
- 最优传输理论研究如何以最小的代价将一个概率分布转换为另一个概率分布。
- OT
路径是在最优传输问题中找到的,将初始分布转换为目标分布的最节省 “成本” 的路径。 - 在图像处理中,最优传输可以用于图像变形、颜色匹配等。
7. 为什么说扩散模型限制于特定的概率路径?
扩散模型通过逐步添加噪声将数据转换为一种简单的噪声分布,然后通过逆过程逐步去除噪声来生成新数据。这一过程可以被视为沿着一个特定的概率路径在数据空间中移动。
「概率路径」通常指的是一个概率过程的演变轨迹,这个过程描述了从一种状态或分布转移到另一种状态或分布的方式。尤其是谈及扩散模型时,概率路径涉及模型如何在数据空间中通过一系列的概率分布变化实现从初始状态(标准高斯分布)到目标状态(自然图像的分布)的转变。
扩散模型中,路径的演变规则是固定的,即如何从一个分布转变到下一个分布的方式是预先定义的,通常是线性或非线性的噪声添加和去除过程。这种固定性使得模型在训练时学习的是如何反向通过这条特定的路径,从而生成新的数据样本。
任何偏离预设路径的尝试都可能导致模型生成不正确或低质量的样本,因为模型没有学习如何处理这些偏离路径的情况。这种限制使得扩散模型在生成过程中缺乏灵活性,无法根据数据的不同特征动态调整路径。
8.
在流匹配中是如何找到
- 构建条件概率路径: 定义均值和标准差随时间线性变化的条件概率路径。
- 计算条件矢量场: 利用条件概率路径的参数,计算对应的条件矢量场。
- 训练模型矢量场: 使用条件流匹配的损失函数,将模型矢量场训练为逼近条件矢量场。
通过选择线性变化的条件概率路径和对应的条件矢量场,流匹配方法成功地找到了符合最优传输性质的
1. Simulation-Free Training of Flows:
在训练生成模型时,可以避免直接求解微分方程,从而提高训练效率。在生成模型,尤其是扩散模型中,通常需要通过模拟一个从数据到噪声的随机过程(即正向过程),然后训练模型逆转这个过程(即逆向过程),以生成新的数据样本。这个过程涉及到求解一个随机微分方程,这在计算上通常是昂贵的。在传统的扩散模型训练中,正向过程是通过模拟一个确定性的微分方程来实现的,这个过程需要在每个时间步上评估神经网络,这导致了较高的计算成本。为了解决这个问题,研究者们提出了一种新的方法,即通过直接回归一个向量场来近似这个过程,而不是直接求解
2. Rectified
Flow Transformer
Models:修正流
- 理论优势:Rectified
Flow
模型通过在数据和噪声之间建立一条直线路径来定义正向过程。这种直接的路径选择在理论上具有更好的属性,因为它减少了在模拟过程中可能累积的误差,并且由于每一步都对应于神经网络的评估,这直接影响了采样速度。 - 简化的训练过程:RF
模型的训练过程相对简单,因为它不需要复杂的积分步骤来模拟过程。这使得 RF 模型在训练时更加高效,尤其是在处理高维数据(如图像)时。 - 性能提升:在第
3 章中,作者通过大规模研究比较了不同的流模型,并展示了 RF 模型在高分辨率文本到图像合成任务中的优越性能。这表明 RF 模型在理解和生成复杂图像方面具有更好的能力。 - 噪声尺度的重新加权:作者在
RF 模型中引入了对噪声尺度的重新加权,这使得模型在训练过程中更加关注于中间时间步,这些时间步在数据到噪声的转换过程中通常更具挑战性。这种加权策略提高了模型在这些关键时间步的性能。 - 可扩展性:RF
模型的架构和训练方法允许模型在不同尺度上进行扩展,这有助于在保持性能的同时增加模型的复杂性。这种可扩展性使得 RF 模型能够适应更广泛的应用场景。 - 实验结果:通过实验,作者展示了
RF 模型在各种评估指标(如验证损失、CLIP 分数和 FID)上相对于其他流模型的优越性。这些实验结果支持了 RF 模型在实际应用中的有效性和优越性能。
3. 时序噪声采样器(Timestep Samplers):在修正流模型(Rectified Flow Models)的训练中起着关键作用。这些采样器的工作方式和提升效率的原因如下:
- 在修正流模型中,数据生成过程被视为一个从数据分布到噪声分布的连续路径。这个过程通常被划分为多个时间步(timesteps),每个时间步对应于路径上的一个点。
- 传统的噪声采样方法可能在所有时间步上均匀地采样,这意味着在训练过程中,模型在每个时间步上接收到的样本数量是相同的。
- 时序噪声采样器则采用一种非均匀的采样策略,它在训练过程中更频繁地采样那些对生成质量影响较大的中间时间步。这是因为在数据到噪声的转换过程中,中间时间步的噪声预测通常更具挑战性,因为它们需要在保留更多数据信息的同时去除噪声。
4. Rectified Flow Transformer
Models
- Multimodal Diffusion
Backbone(多模态扩散骨干)是模型的一部分,它处理图像和文本两种模态的信息。在修正流
Transformer 模型中,这个骨干(Multimodal Diffusion Backbone)负责将文本和图像的潜在表示结合起来,并通过 Transformer 的自注意力机制进行处理。 - 这种结合允许模型在生成过程中同时考虑文本提示和图像内容,从而生成与文本描述相匹配的高质量图像。多模态扩散骨干的设计使得模型能够在图像和文本之间实现双向信息流,这对于理解和生成复杂的图像内容至关重要。
总的来说,Rectified Flow Transformer
Models
自回归
DALL-E
[1] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,”in ICML, 2021.
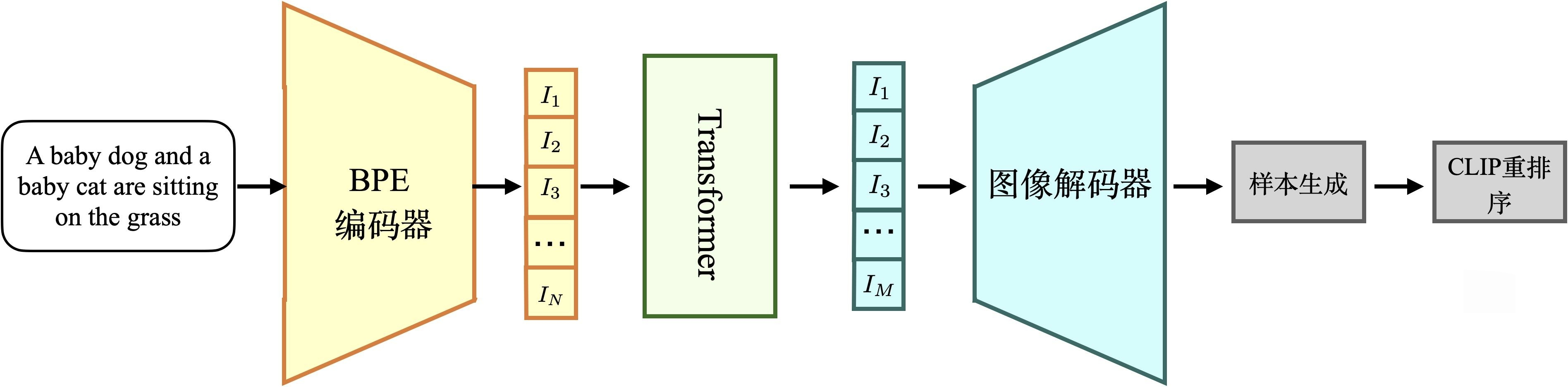
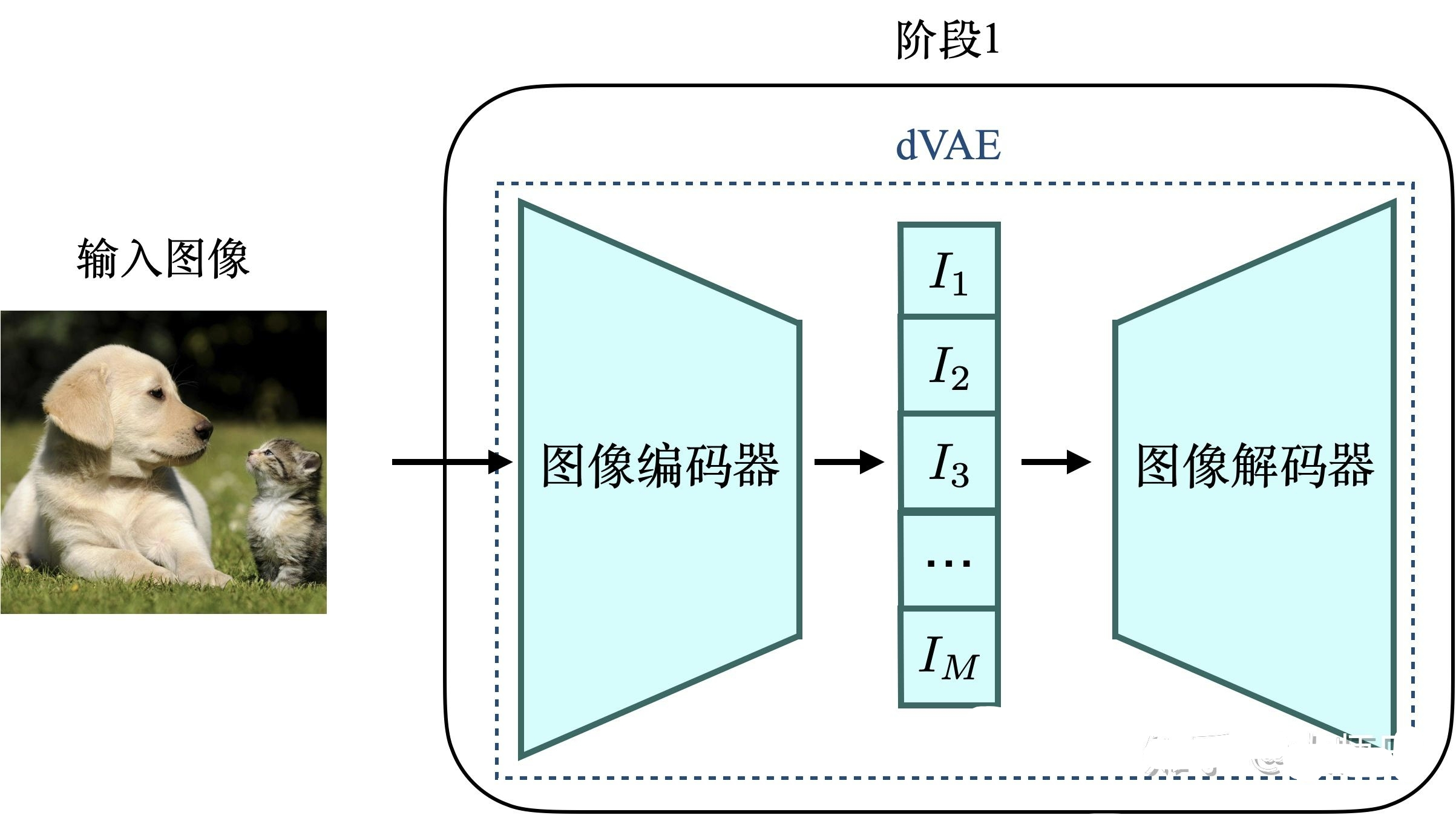
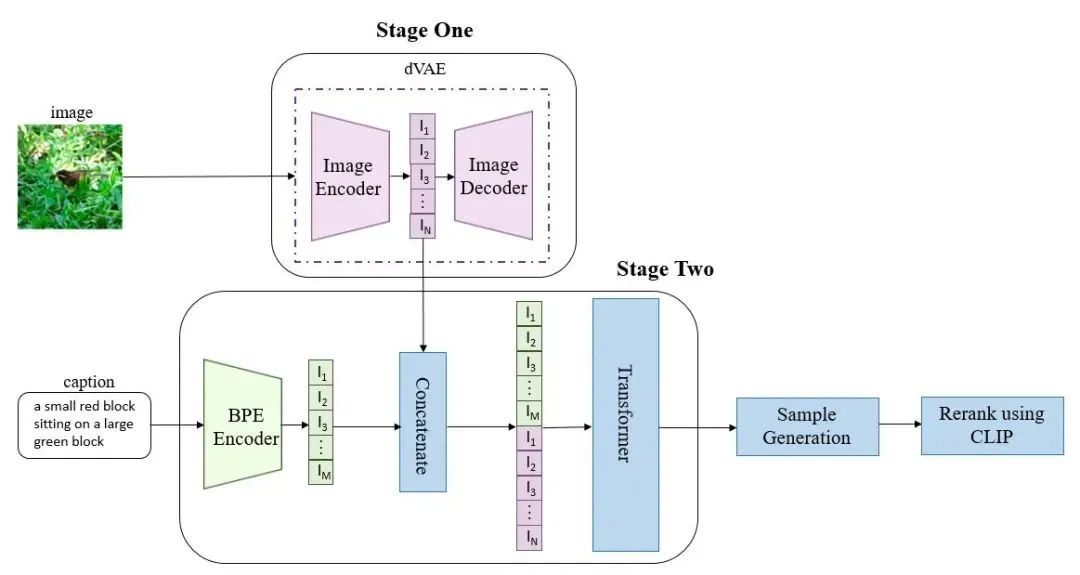
CogView
[3] M. Ding, Z. Yang, W. Hong, W. Zheng, C. Zhou, D. Yin, J. Lin, X. Zou, Z. Shao, H. Yang et al., “Cogview: Mastering text-toimage generation via transformers,” in NeurIPS, 2021.
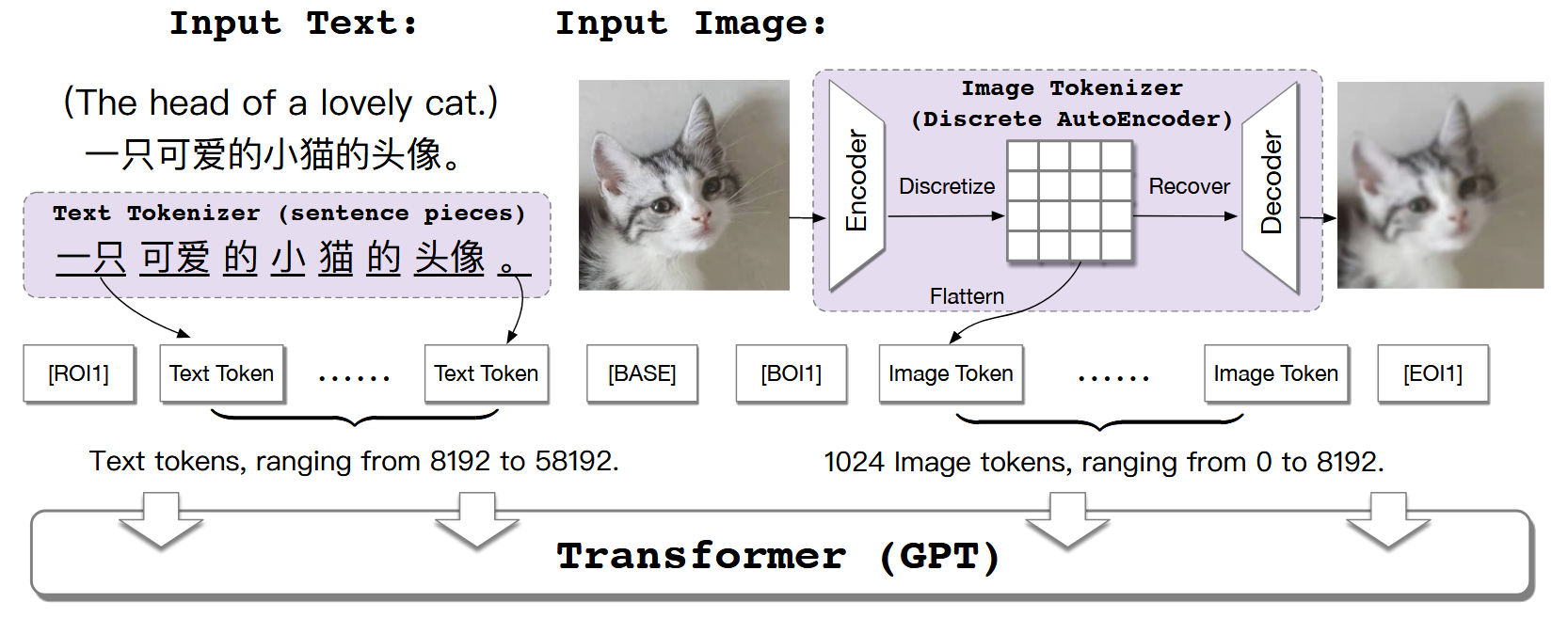
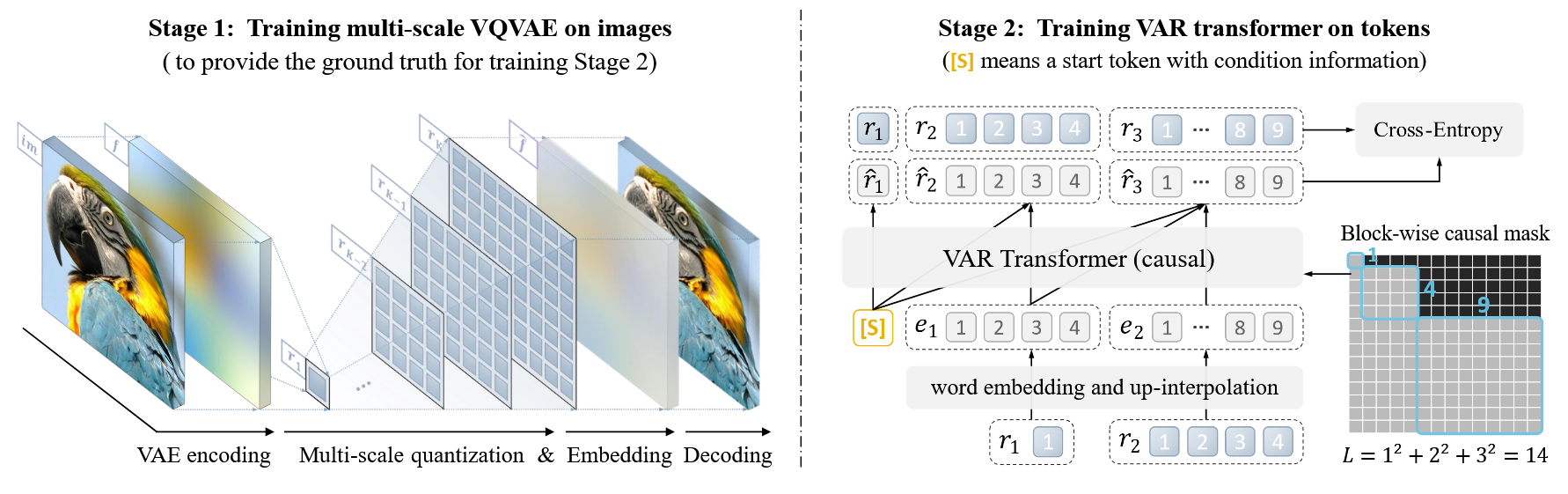
VAR
[2] Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang, “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction,”in NeurIPS, 2024.