自然语言处理与大模型
自然语言是人类社会发展过程中自然产生的语言,特指人类使用的语言。
第
基本概念
术语理解
自然语言理解是探索人类自身语言能力和语言思维活动的本质,研究模仿人类语言认知过程的自然语言处理方法和实现技术的一门学科。它是人工智能早期研究的领域之一,是一门在语言学、计算机科学、认知科学、信息论和数学等多学科基础上形成的交叉学科。(宗成庆,黄昌宁)
计算语言学是通过建立形式化的计算模型来分析、理解和生成自然语言的学科,是人工智能和语言学的分支学科。计算语言学是典型的交叉学科,其研究常常涉及计算机科学、语言学、数学等多个学科的知识。与内容接近的学科自然语言处理相比较,计算语言学更加侧重基础理论和方法的研究。 (常宝宝)
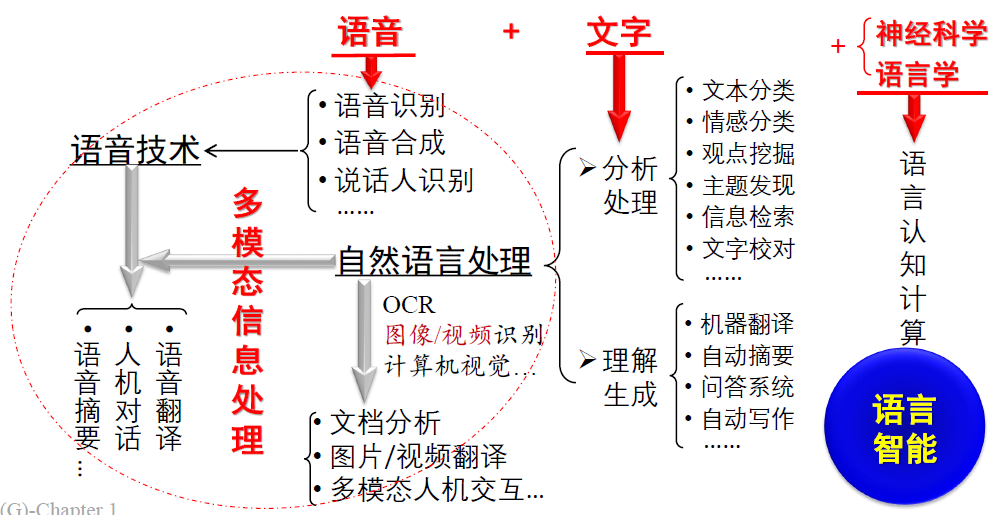
自然语言处理是研究如何利用计算机技术对语言文本(句子、篇章或话语等)进行处理和加工的一门学科,研究内容包括对词法、句法、语义和语用等信息的识别、分类、提取、转换和生成等各种处理方法和实现技术。(宗成庆,黄昌宁)
研究内容(传统划分)
问题挑战
- 语言中大量存在不确定性——歧义 (ambiguity)
- 语言表达中大量地使用缩略语和隐喻。
- 大量存在未知的语言现象
- 新词 、人名、地名、 术语、网络用语等;
- 新含义;
- 新用法和新句型等。
- 知识表示和获取的复杂性
- 知识(尤其常识)往往是模糊、隐蔽、密切关联地通过自然语言描述的。
- 不同语言之间存在概念差异
- 由于历史、文化、宗教和思维方式等差异导致语义概念不对等。
- 关于
“理解” 的标准 - 如何判断计算机系统的智能?——图灵实验
(Turing test)
- 如何判断计算机系统的智能?——图灵实验
- 人脑是如何学习 、 记忆和理解语言的?
- 语言学、心理学
- 认知科学、神经科学
- 计算机科学
- 统计学、信息论
- 背景知识、常识等
技术方法
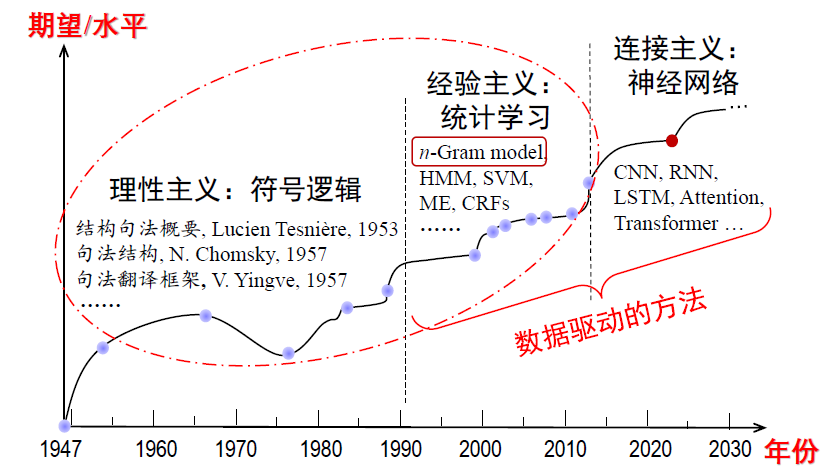
理性主义
通过对一些代表性语句或语言现象的研究得到对人的语言能力的认识,归纳语言使用的规律,以此分析、推断测试样本的预期结果 。
基本思路 :基于规则的分析方法建立符号处理系统
- 设计规则 :N + N → NP
- 标注词典 :#工作, N(uc); V;
- 推导算法 :归约、推导、歧义消解方法…
知识库 + 推理系统 → NLP 系统
经验主义
利用大规真实语言数据,借助人的帮助(标注数据和筛选特征等),统计发现语言使用的规律及其可能性(概率)大小,以此为依据计算预测测试样本的可能结果。统计单元是离散事件(词、短语、词性等 )。
问题求解思路:基于大规模真实数据建立统计学习模型
- 收集标注数据:真实性、代表性、标注……
- 统计建型:模型的复杂性、有效性、参数训练……
语言数据收集、标注 + 统计模型 → NLP 系统
连接主义
利用超大规模真实语言数据,统计发现语言使用的规律及其可能性(概率)大小,以此为依据计算预测测试样本的可能结果。统计单元采用连续的实数空间表示(向量),充分利用和精细刻画大范围上下文信息,建立统一的模型框架。
问题求解思路:基于大规模真实数据建立深度学习模型
- 收集标注数据:真实性、代表性、标注……
- 神经网络建模:模型的复杂性、有效性、参数训练……
大数据 + 大模型 + 大算力 → NLP 系统
以机器翻译为例
- 基于规则的方法
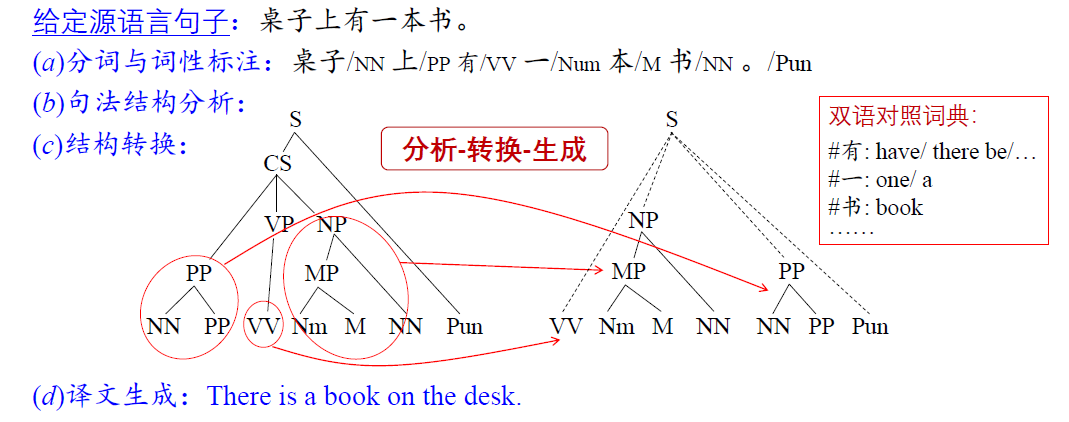

- 统计翻译方法

- 基于神经网络的翻译方法


第
概率论略览

随机过程(stochastic process)

随机过程的平稳性


例如今天的人民日报内容与昨天的人民日报内容从统计学的角度来说是一致的。
随机过程的遍历性

遍历性的核心思想是:对于某些随机过程,从
我们可以通过一个经典的比喻来理解:
- 集合平均:想象一下,你想知道全国
30 岁男性的平均身高。 - 方法
A(集合平均):在某个特定时间点,你找来了 1 万名 30 岁的男性,测量他们的身高然后取平均。这相当于对随机过程(30 岁男性的身高)在所有可能的样本(所有 30 岁男性) 上求平均。 - 这个平均值是理论上的期望值。
- 方法
- 时间平均:现在,换一种方法。
- 方法
B(时间平均):你选定一个男孩,从他出生开始,每年在他生日那天测量他的身高,一直测到他 60 岁。然后,你从他 30 岁那年的测量值开始,取到 40 岁,这 10 个数据的平均值作为 “30 岁男性平均身高” 的估计。 - 这相当于对随机过程(这个男性的身高变化)在时间轴上求平均。
- 方法
那么问题来了:方法
如果答案是
齐夫定律
在自然语言的大规模文本数据上统计,一个单词出现的频率与它在频率表中的名次(序号)成反比 。
例如,在 100 万单词的 Brown 语料库中,the 出现的频率最高,出现了
69971 次,占比大约 7 %,名列第一。 单词 of 出现了 36411 次,占比约为
3.5%, 名列第二。 and 出现了 28852 次,约占 2.9%, 名列第三 。
粗略的规律是:按词频顺序,第 r (r
一般而言,假设词汇 w
出现的频率为 f
,在排序列表中处于 r
号位置上那,么 f 和 r
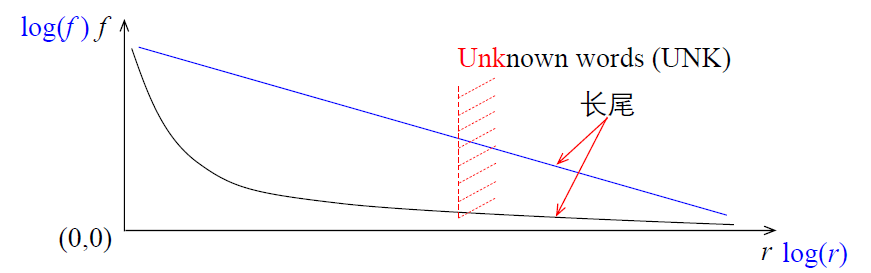
从统计结果看,少数高频词占了整个语料规模的大部分比例,而大部分词汇属于低频词
。 这种现象通常被称为长尾效应 (long tail effect),
相应的词汇称为长尾词
信息论基础
熵 (entropy)
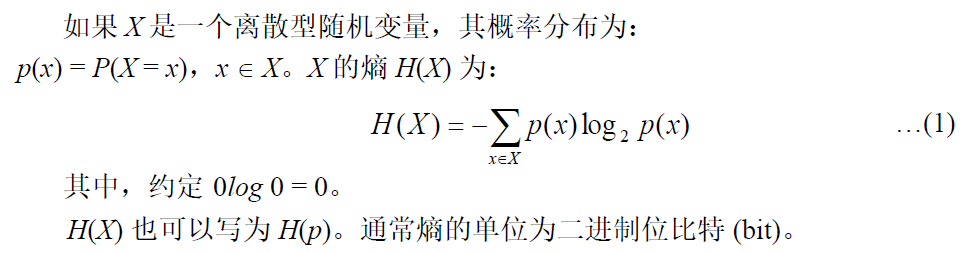
熵表示随机变量 X
每个具体取值
联合熵
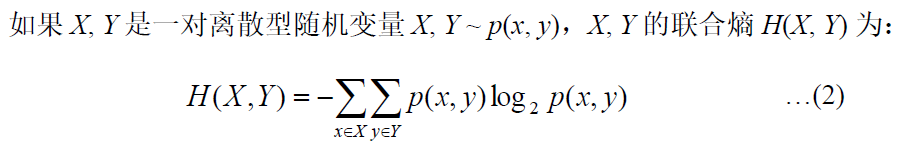
联合熵实际上就是描述一对随机变量平均所需要的信息量。
条件熵

连锁规则:H(X, Y) = H(X) + H(Y|X)
相对熵
或称
Kullback-Leibler divergence, K-L 距离,或 K-L 散度
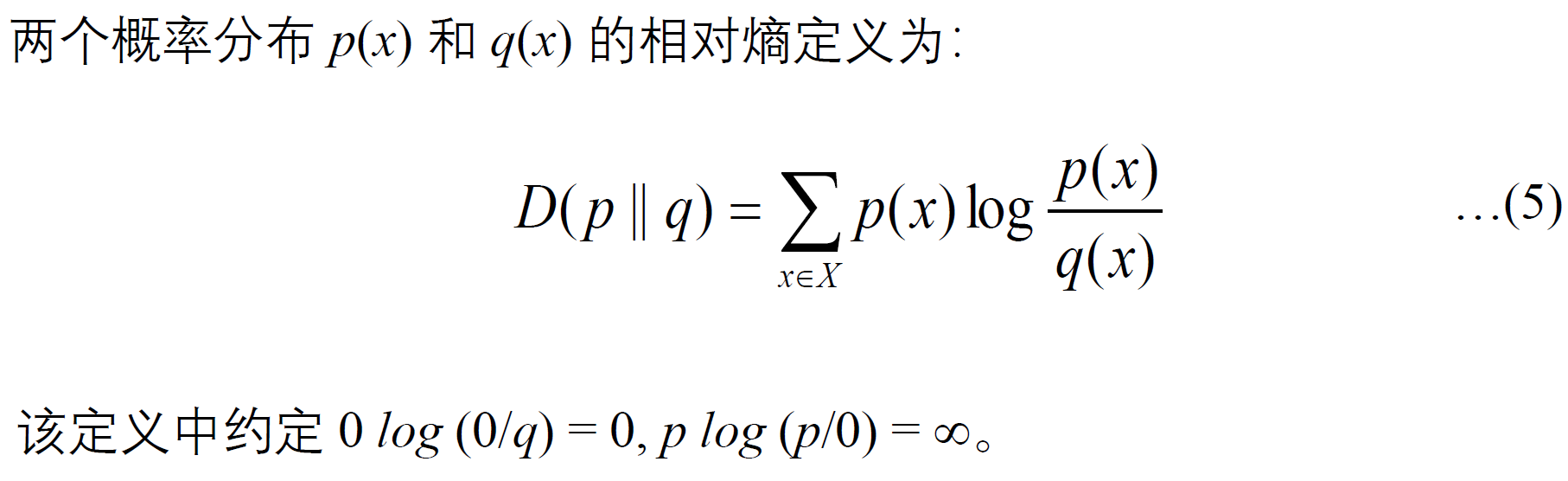
相对熵常被用以衡量两个随机分布的差距。当两个随机分布相同时,
其相对熵为
交叉熵

交叉熵衡量的也是两个模型分布之间的差异。


由此,我们可以根据模型 q 和一个含有大量数据的 L 的样本来计算交叉熵。在设计模型 q 时,我们的目的是使交叉熵最小,从而使模型最接近真实的概率分布
p(x)。
相对熵和交叉熵的对比分析
交叉熵
= 熵 + 相对熵:H(p, q) = H(p) + D(p||q) 在机器学习中,经常用
p(x) 表示真实数据的概率分布,由于真实数据的概率分布往往无法获得,所以一般通过大量的训练数据来近似。 假设我们通过某个模型得到了训练数据的概率分布
q(x),由于真实数据的概率分布 p(x) 往往是不变的,因此最小化交叉熵 H(p, q) 等效于最小化相对熵 D(p||q)。 习惯上机器学习算法中通常采用交叉熵计算损失函数 。
困惑度

语言模型设计的任务就是寻找困惑度最小的模型,使其最接近真实的语言分布。
互信息

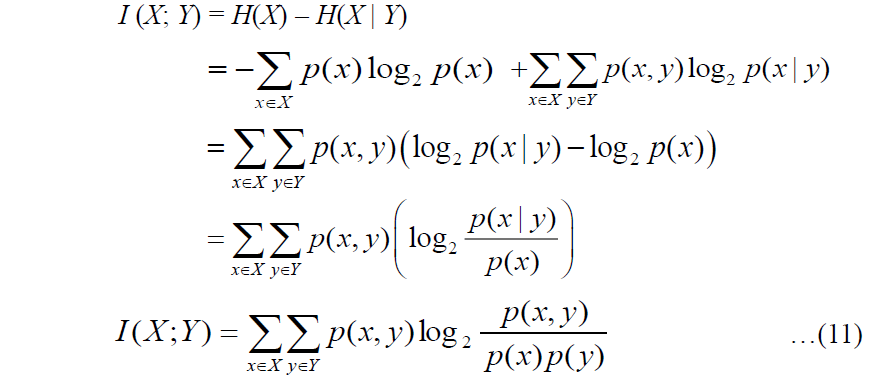
互信息
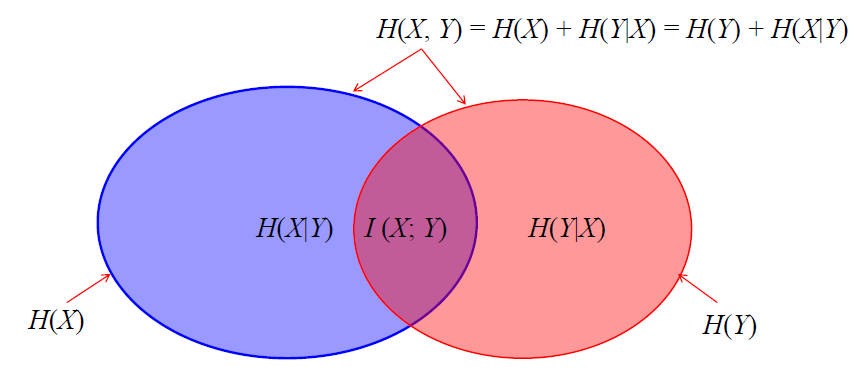
由于
理论上,互信息值越大,表示两个汉字之间的结合越紧密,越可能成词。反之,断开的可能性越大。当两个汉字
说明:两个单个离散事件之间的互信息通常称为点式互信息,点式互信息可能为负值。两个随机变量之间的互信息称为平均互信息,平均互信息不可能为负值。
统计学习概念
统计学习方法
- 数据驱动
- 对数据进行预测与分析
- 以方法为中心构建模型
统计学习类型
- 监督学习 (supervised learning)
- 给定有限的、人工标注好的大量数据,假设这些数据是独立同分布产生的
(训练集, training data) - 假设要学习的模型属于某个函数的集合,即假设空间 (hypothesis)
- 应用某(些)个评价准则 (evaluation
criterion),从假设空间中选取最优的模型使其对已知的训练数据和未知的测试数据
(test data)
在给定的评价准则下有最优的预测
- 给定有限的、人工标注好的大量数据,假设这些数据是独立同分布产生的
- 非监督学习 (unsupervised learning)
- 半监督学习 (semi supervised learning)
- 强化学习 (reinforcement learning)
监督学习
一般步骤: ①获得一个有限的训练数据集合 ②确定包含所有可能的模型的假设空间,即学习模型的集合 ③确定模型选择的准则,即学习的策略 ④通过学习方法选择最优模型 ⑤利用学习到的最优模型对新数据进行预测或分析
问题的形式化:
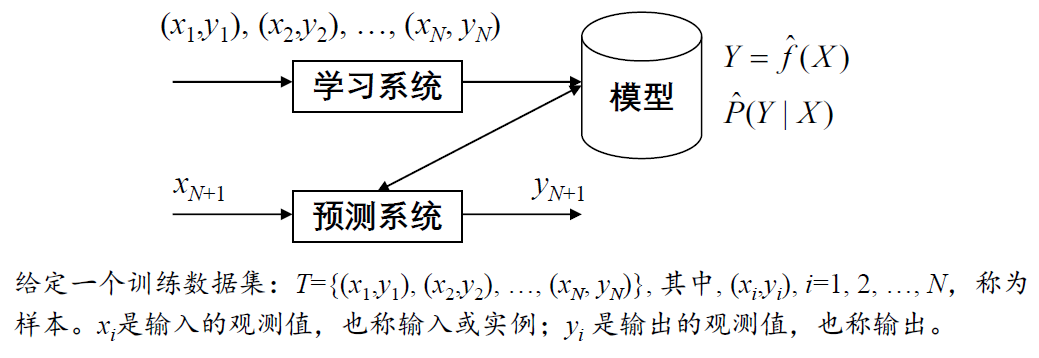
模型的类别
生成式方法 (generative model)

区分式
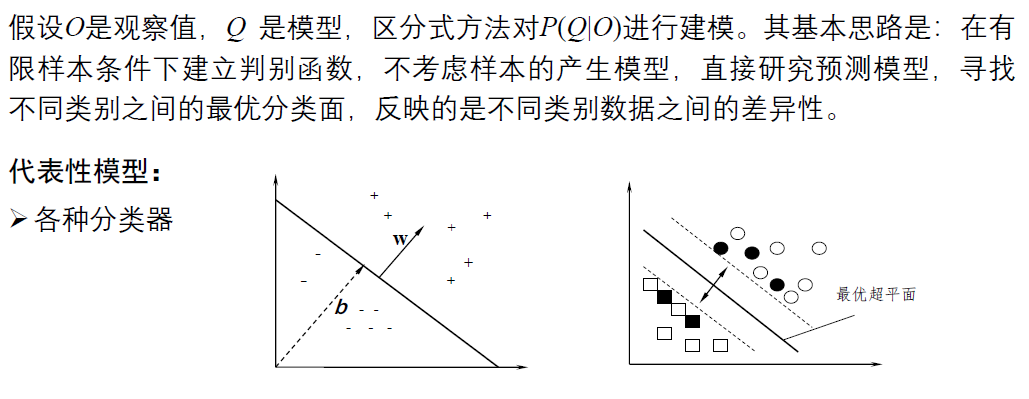
相关概念
- 语料 (corpus)/ 语料库 (corpus base):语言资源(数据集)
- 训练集 (training data):用于模型参数训练
- 开发集 (development data):用于模拟测试,优化参数
- 测试集 (test data):测试模型或模型实际处理的数据
- 过拟合 (overfitting):模型只在训练集上性能优良
- 欠拟合 (under-fitting) :模型在训练集上性能远未达到最优
- 鲁棒性 (robustness): 测试集的差异对模型性能影响不大
常用的统计模型

最大熵模型及应用
问题提出
任何一种语言中,一词多义(歧义)现象是普遍存在的。如何区分不同上下文中的词汇语义,就是词汇歧义消解问题,或称词义消歧 (word sense disambiguation, WSD) 。 词义消歧是自然语言处理中的基本问题之一。

解决思路
每个词表达不同的含意时其上下文(语境)往往不同,也就是说,不同的词义对应不同的上下文,因此,如果能够将多义词的上下文区别开,其词义自然就明确了。 词义消歧变成一个上下文分类任务。

基本的上下文信息:词、词性、位置。
最大熵分类器
基本原理
在只掌握关于未知分布的部分知识的情况下,符合已知知识的概率分布可能有多个,使熵值最大的概率分布能够最真实地反映事件的分布情况。由于熵定义了随机变量的不确定性,当熵最大时,随机变量最不确定 。 也就是说,在已知部分知识的前提下,关于未知分布最合理的推断应该是符合已知知识最不确定或最大随机的推断 。
最大熵模型的核心思想非常直观且深刻:在满足已知事实(约束条件)的所有可能模型中,选择那个
我们可以通过一个简单的例子来理解:
问题: 预测一个骰子每个面朝上的概率。
- 没有任何信息时(零约束): 我们只知道这是个六面骰子。那么最公平、最不会引入任何主观偏见的假设就是:每个面朝上的概率都是 1/6。这个分布(均匀分布)就是熵最大的分布。任何其他的分配方式(比如认为
1 点概率更大)都是我们在没有证据的情况下强加的假设。 - 已知一个信息时(一个约束): 现在我们通过观察得知:“点数为
1 的概率是点数为 2 的概率的两倍”,即 P(1) = 2P(2)。 那么,在所有满足 P(1) = 2P(2) 的概率分布中,我们选择最均匀的那个。计算结果是: P(1) = 2/7, P(2) = 1/7, P(3) = 1/7, P(4) = 1/7, P(5) = 1/7, P(6) = 1/7。 这个分布就是满足该约束下的最大熵分布。我们没有对 3、4、5、6 点做任何额外的假设,所以让它们保持相等。 哲学解读: 最大熵原理承认我们所知道的(约束条件),但对未知部分不做任何主观假设,保持最大的不确定性。这是一种非常保守和稳健的建模原则。
让熵最大是对未知分布推断最合理的准则。换句话说,推断未知分布合理的做法是将已知的先验知识作为约束,让未知分布的熵最大。
模型定义




经推导,有:

确定特征函数



举例:

如果上下文条件由如下三类信息表示:
⑴特征的类型:词形、词性、词形+词性,3
特征选择一般有三种方法:
①从候选特征集中选择那些在训练数据中出现频次、超过一定阈值的特征
②利用互信息作为评价尺度从候选特征集中选择满足一定互信息要求的特征
③利用增量式特征选择方法 (Della Pietra et al )
获取λ参数
利用

GIS


整个过程
条件随机场及应用
模型提出
在
基本思想:给定观察序列 X ,输出标识序列 Y ,通过计算
模型定义





具体解释如下:
1. 核心思想:什么是
简单来说,CRF
我们可以拆解这三个关键词来理解:
- 判别式模型:
- 与生成式模型(如朴素贝叶斯、隐马尔可夫模型)不同,判别式模型直接学习条件概率 P(Y|X),即给定输入序列 X,输出最可能的标签序列 Y。
- 打个比方:生成式模型是学习
“每个动物长什么样(P(特征|类别))”,然后根据样子来分类;判别式模型是直接学习 “如何区分猫和狗(P(类别|特征))”。CRF 关心的是给定一句话(观测序列 X),最可能的词性标注序列(标签序列 Y)是什么,而不去建模这句话本身产生的概率 P(X)。
- 概率图模型:
- CRF
使用一个无向图(通常是线性链)来表示变量之间的依赖关系。 - 图中的节点代表随机变量(标签 Y 和观测 X),边代表变量之间的依赖关系。
- CRF
- 条件随机场:
- “条件”
体现在模型是直接对 P(Y|X) 建模。 - “随机场”
可以理解为一组随机变量,它们在一个图结构中,其联合概率分布可以由图的势函数来定义。
- “条件”
CRF
2. 数学模型:CRF
我们以最常用的线性链条件随机场 为例,它非常适合序列问题。
2.1 图结构
线性链
1 | |
Y1, Y2, ..., Yn构成一个线性链,表示标签序列。Yi与Yi-1和Yi+1直接相连。X1, X2, ..., Xn是观测序列。- 每个标签
Yi都依赖于整个观测序列 X(理论上),但在实践中,通常只依赖于当前时刻的观测Xi或一个局部窗口。
这个结构意味着,标签序列 Y 的联合概率,在给定观测序列 X 的条件下,是由这个图结构所定义的。
2.2 特征函数和能量函数
CRF
CRF
- 状态特征函数:关联一个单个的标签节点
Yi和观测序列 X。- 形式:
s_l(Yi, X, i) - 含义:在位置 i,当标签为
Yi,并且观测序列是 X 时,这个特征有多强。 - 例子:在词性标注中,一个特征函数可能是:
如果单词 Xi 以,那么返回 1,否则返回 0。‘-ing’ 结尾,并且标签 Yi 是 ‘动词 (VBG)’
- 形式:
- 转移特征函数:关联一对相邻的标签节点
(Yi-1, Yi)和观测序列 X。- 形式:
t_k(Yi-1, Yi, X, i) - 含义:在位置 i,当从上一个标签
Yi-1转移到当前标签Yi,并且观测序列是 X 时,这个特征有多强。 - 例子:在词性标注中,一个特征函数可能是:
如果前一个标签 Yi-1 是,那么返回 1,否则返回 0。‘冠词 (DT)’,并且当前标签 Yi 是 ‘名词 (NN)’
- 形式:
每个特征函数 f_m(可以是状态特征 s_l
或转移特征 t_k)都有一个对应的权重
λ_m,这个权重在训练中学得。权重表明了该特征的重要性。正权重意味着我们鼓励这种情况出现,负权重意味着我们抑制这种情况。
2.3 条件概率公式
结合所有特征函数和它们的权重,线性链
- 指数内部:对序列中每一个位置
i,将所有状态特征和转移特征的加权和累加起来。这个和可以看作是整个标签序列
Y 和观测序列 X 的
“兼容度得分”。 - Z(X):归一化因子,也称为配分函数。它确保所有可能的标签序列
Y 的概率之和为
1。
Z(X) = Σ_{Y} exp( ... ),计算它需要枚举所有可能的 Y,在长序列上计算量很大。 - exp(.):将得分转化为正数,并通过归一化转化为概率。
模型实现
特征选取
与最大熵模型采用的方式相同
特征选择一般有三种方法: ①从候选特征集中选择那些在训练数据中出现频次、超过一定阈值的特征 ②利用互信息作为评价尺度从候选特征集中选择满足一定互信息要求的特征 ③利用增量式特征选择方法 (Della Pietra et al )
从候选特征集中选择特征。 (比较复杂) 选定特征之后确定特征函数 f,假设共有 k(k > 0) 个特征函数。
参数训练


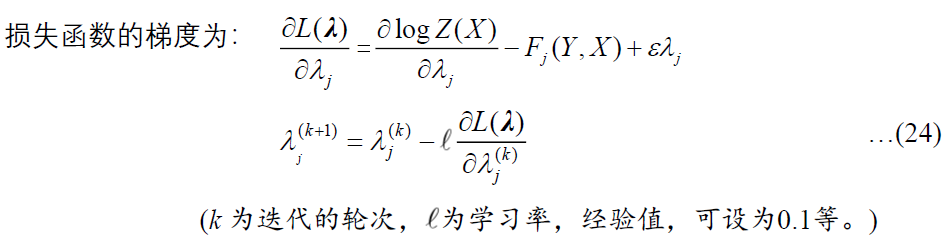
算法描述:

解码
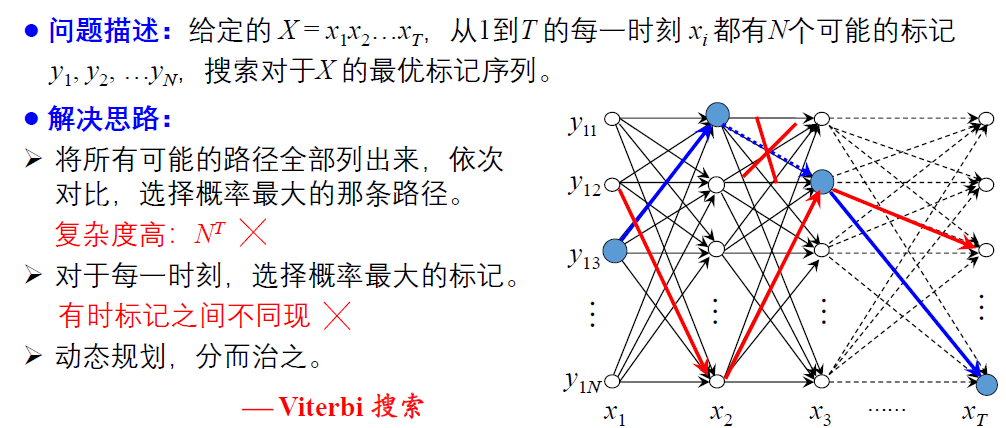

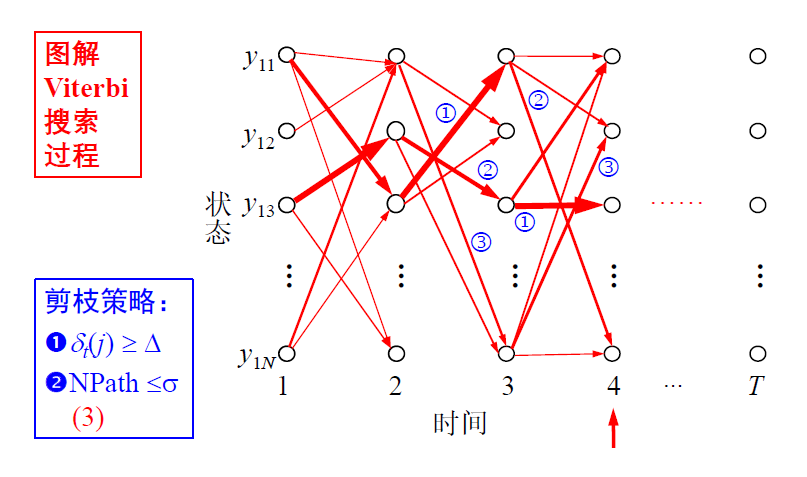

CRFs 应用举例
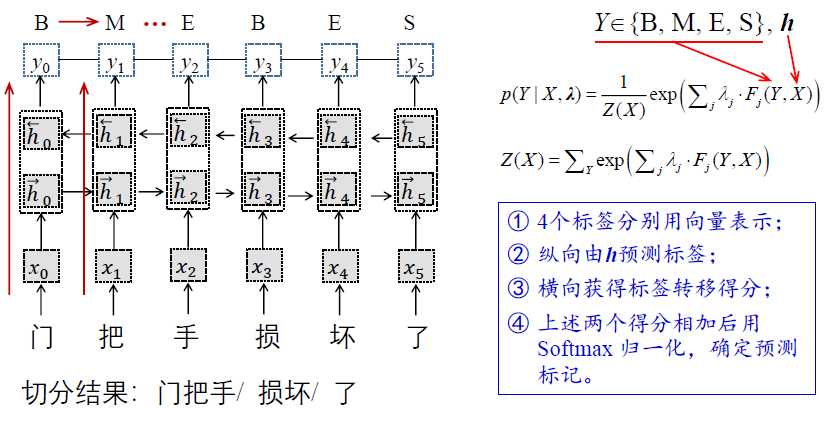
基于字标注的分词方法
基本思想:将分词过程看作是字的分类问题,每个字在构造一个特定的词语时都占据着一个确定的构词位置,即词位 。 一般而言,每个字只有 4 个词位 词首 (B) 、 词中 (M) 、词尾 (E) 和单独成词 (S) 。







第
模型定义
问题提出
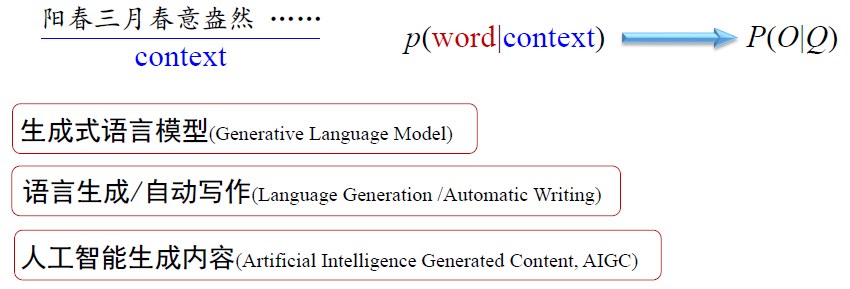
如何计算一段文字(句子)的概率?
阳春三月春意盎然,少先队员脸上荡漾着喜悦的笑容,鲜艳的红领巾在他们的胸前迎风飘扬。

问题:随着历史基元数量的增加,不同的”
问题的解决方法


这种语句概率计算模型称为语言模型

参数估计
基本思路
- 收集、标注大规模样本,我们称其为训练数据
/ 语料 (training data/corpus) - 利用最大似然估计
(maximum likelihood evaluation,MLE) 方法计算概率
实现方法




数据平滑
基本思想
调整最大似然估计的概率值,使零概率增值,使非零概率下调,劫富济贫,消除零概率,改进模型的整体正确率。
- 目标:测试样本的语言模型困惑度越小越好。
- 约束:∑wip(wi|wi − n + 1j − 1) = 1
回顾—困惑度:

数据平滑方法
- 加
1 法 (additive) - 减值法
/ 折扣法 (discounting) - 删除插值法
(deleted interpolation)
加




N
模型应用
以汉语分词为例

方法描述

一种改进的实现方法



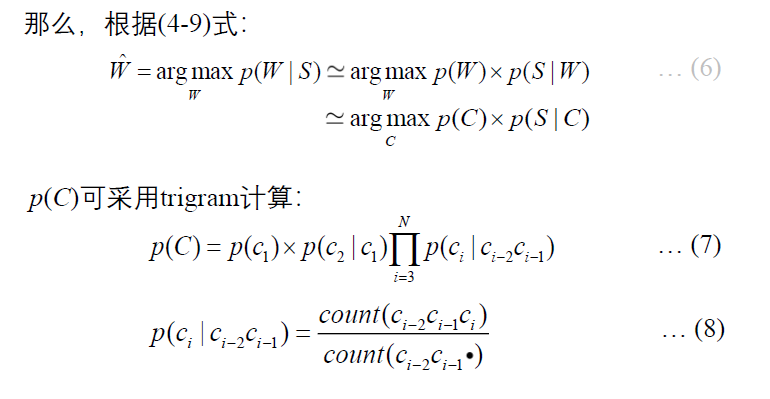

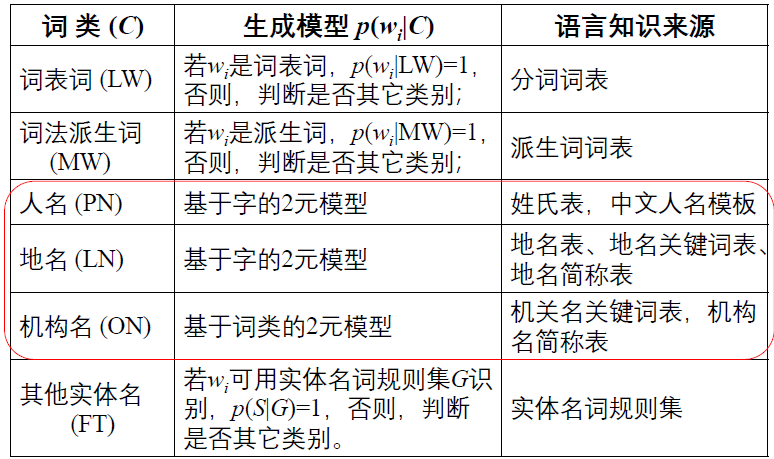
模型训练
- 在词表和派生词表的基础上,用一个基本的分词工具切分训练语料;专有名词通过一个专门模块标注,实体名词通过相应的规则和有限状态自动机标注,由此产生一个带词类别标记的初始语料;
- 用带词类别标记的初始语料,采用最大似然估计方法估计语言模型的概率参数公式
(7); - 用得到的模型对训练语料重新切分和标注,得到新的训练语料;
- 重复
2、3 步,直到系统的性能不再有明显的变化为止。



实验语料
- 词表词: 98,668 条、派生词: 59,285 条;
- 训练语料: 88MB 新闻文本;
- 测试集: 247,039 个词次,分别来自描写文、叙述文、说明文、口语等。
测试指标

模型应用

N-元文法模型的广泛应用

第
- 这里所说的
“传统 NLP 技术” 是指基于神经网络的深度学习方法出现之前的自然语言处理技术,包括理性主义方法和经验主义方法。 - 传统的 NLP 方法通常需要如下三个步骤:词语切分与命名实体识别;句法分析;语义分析。因此,本章简要介绍以下三方面关键技术。
4.1 词语切分与命名实体识别
分词要点
切分意义
- 词是语言中能够独立使用的最小的语言单位;
- 词语切分在传统的 NLP 方法中是句子结构分析、语义分析和篇章分析等后续任务完成的前提和基础;
- 到目前为止,所有的 NLP 方法,包括深度学习方法,都是以词或子词为统计基元建模实现的;
- 词语切分具有广泛的应用,如词频统计,词典编纂,文章风格研究,文献处理,文本校对,简繁体转换等 。
汉语自动分词中的主要问题


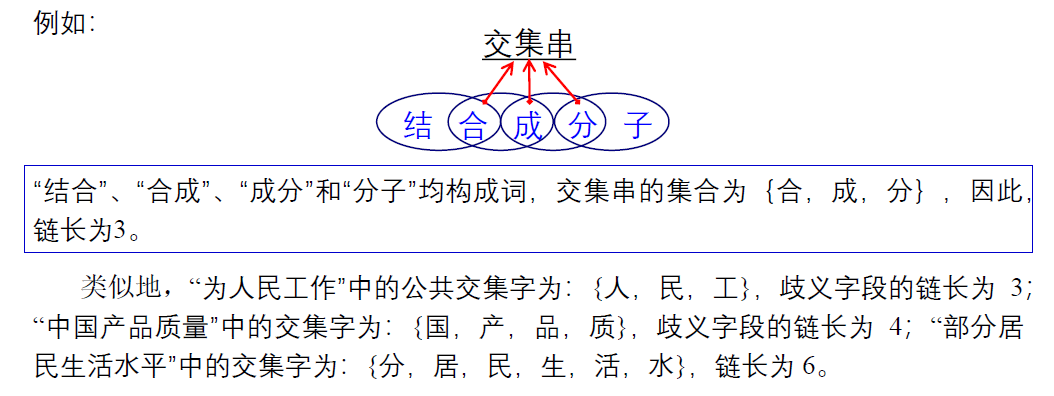


汉语自动分词的基本原则
- 语义上无法由组合成分直接相加而得到的字串应该合并为一个分词单位。
- 语类无法由组合成分直接得到的字串应该合并为一个分词单位。


汉语自动分词的辅助原则
操作性原则,富于弹性,不是绝对的。
- 切分原则
1:有明显分隔符标记的应该切分之。 - 分割标记指标点符号或一个词。如:上、下课->
上 / 下课 - 洗了个澡->
洗 / 了 / 个 / 澡
- 分割标记指标点符号或一个词。如:上、下课->
- 切分原则
2:结构复杂、合并起来过于冗长的词尽量切分。 - 合并原则
1:附着性语(词)素与前后词合并为一个单位。 - 合并原则
2:使用频率高或共现率高的字串尽量合并。 - 合并原则
3:双音节加单音节的偏正式名词合并成一个分词单位。 - 合并原则
4:双音节结构的偏正式动词应尽量合并。





评价指标


切分方法

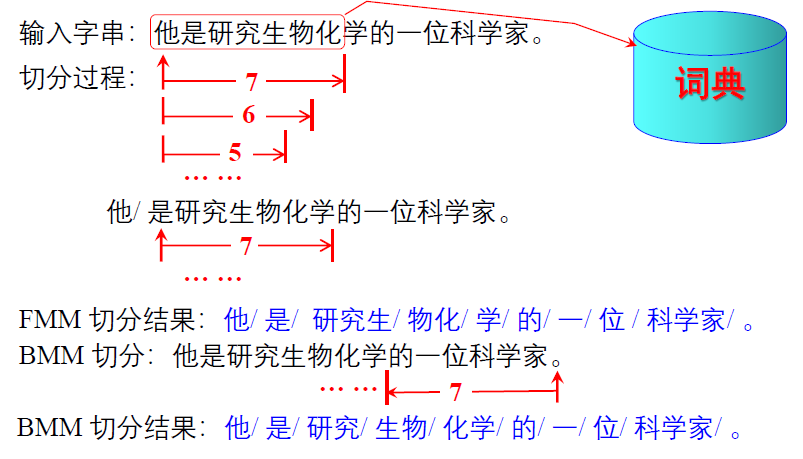
1. 最大匹配法(Maximum Matching, MM)
按照切分方向分为:
- 正向最大匹配算法 (Forward MM, FMM)
- 逆向最大匹配算法 (Backward MM,BMM)
- 双向最大匹配算法 (Bi-directional MM)
基本思路:
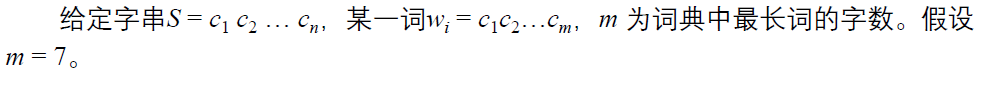
FMM

例子:“南京市长江大桥”
假设词典中同时包含 “南京市”(Nanjing City)和 “南京市长”(Nanjing Mayor)。
算法解释过程:
- 扫描与匹配: 算法从句子的最左边开始扫描,试图在词典中找到最长的匹配词。
- 贪婪选择:
虽然
“南京市” 是一个词,但算法发现 “南京市长”(4 个字)比 “南京市”(3 个字)更长且也在词典中。 - 切分结果: 根据
“正向最大” 原则,算法会优先切出 “南京市长”,剩下的字符继续匹配。
正向最大匹配(FMM)的结果:
南京市长 / 江 / 大桥 (意思变成了:南京市的市长,名叫江大桥)
与正向匹配相反,RMM 的核心逻辑是:从右往左(从句子末尾)开始扫描。结果:
南京市 / 长江 / 大桥
双向最大匹配算法(Bi-directional Maximum Matching,
BiMM) 的逻辑其实非常像一位公正的
- 规则 1:词数越少越好(非碎片化原则)
- 规则 2:单字越少越好(惩罚单字原则)
| 选手 | 切分结果 | 词总数 | 单字数 (决胜点) |
|---|---|---|---|
| 正向 (FMM) | 南京市长 / 江 / 大桥 |
3 |
1 |
| 逆向 (BMM) | 南京市 / 长江 / 大桥 |
3 |
0 |
裁判判定:
- 先看词总数:都是 3 个词,打平。
- 再看单字数:FMM 有 1 个单字(江),RMM 有 0 个。
- 结果:RMM 获胜! 最终输出
“南京市 / 长江 / 大桥”。
方法评价:

2. 基于语言模型的分词方法
基本思路:

见第三章
方法评价:

3.
由字构词的分词方法

见第二章
方法评价:

4. 生成式方法与区分式方法的结合

5. 基于神经网络的分词方法
可用的分词工具:

命名实体识别





领域差异和生词识别是分词和 NER 面临的最大挑战
子词压缩

基本思路:
- 对于英语等屈折语文本,可直接用双字节编码算法
(Pair Encoding, BPE) 算法进行字符压缩。 - 对于汉语文本,如果有很好的分词工具,先对文本进行词语切分,在切分结果的基础上利用
BPE 算法进行单字压缩,合并那些最大次数的相邻汉字或字符。
BPE
①对邻近的两个字符
②将α最大的两个邻近字符
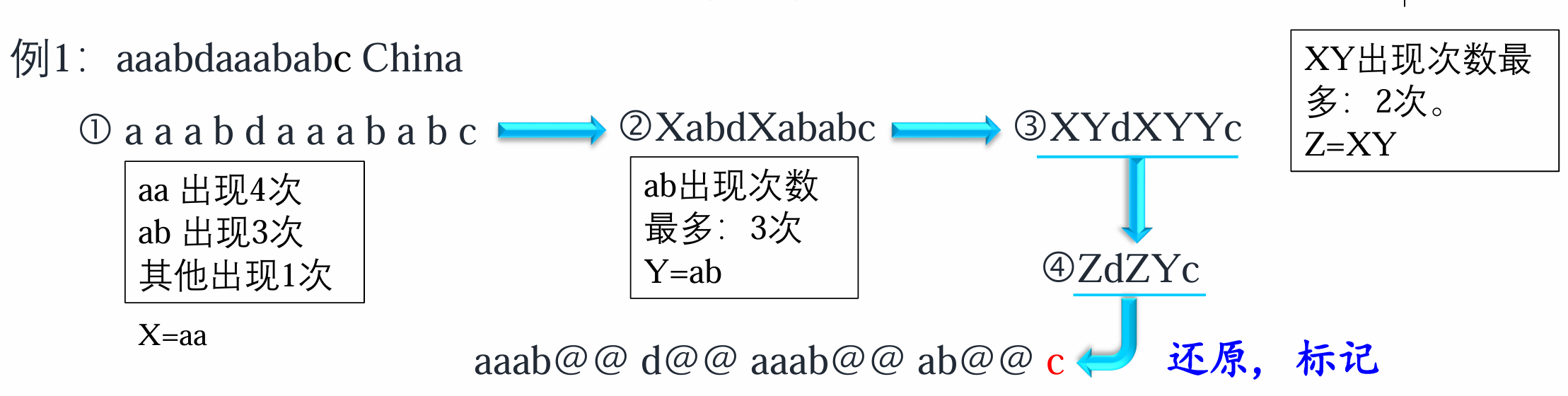
词性标注
词性或称词类
如在汉语中,词类分为两大类:实词
词性标注的任务是让系统自动对词汇标注词性标记。
标注集的确定原则:不同语言中,词性划分基本上已经约定俗成。 自然语言处理中对词性标记要求相对细致。
一般原则:
- 标准性 : 普遍使用和认可的分类标准和符号集;
- 兼容性 : 与已有资源标记尽量一致,或可转换;
- 可扩展性 :扩充或修改。
标注方法:
- 基于规则
/ 有限状态机的词性标注方法 - 基于统计模型的词性标注方法
- HMM:分词与词性标注一体化方法
- CRFs:序列标注方法
- 规则和统计方法相结合的词性标注方法
性能评价指标:准确率
4.2 句法分析
1. 短语结构分析
短语结构分析
例如,给定如下句子:他还提出一系列具体措施和政策要点。

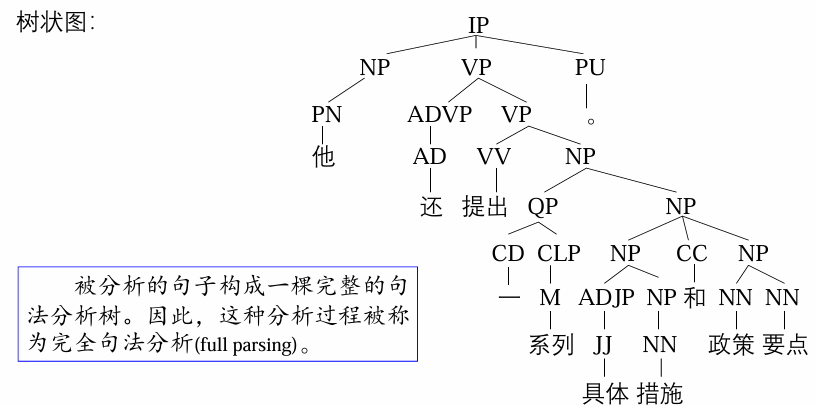
有时候,并不需要分析整个句子的完整结构,而只需要分析句子中的某些短语,如

如果只分析句子中某种类型的短语结构,这种分析过程称为局部句法分析
设置句法分析器的目标:实现高准确率、高鲁棒性
基本方法:
- 基于
CFG 规则的分析方法 - 线图分析法(chart parsing)
- CYK
分析算法 - Earley(厄尔利)算法
- LR
算法 /Tomita 算法
- 基于
PCFG 的分析方法 - 基于神经网络的分析方法
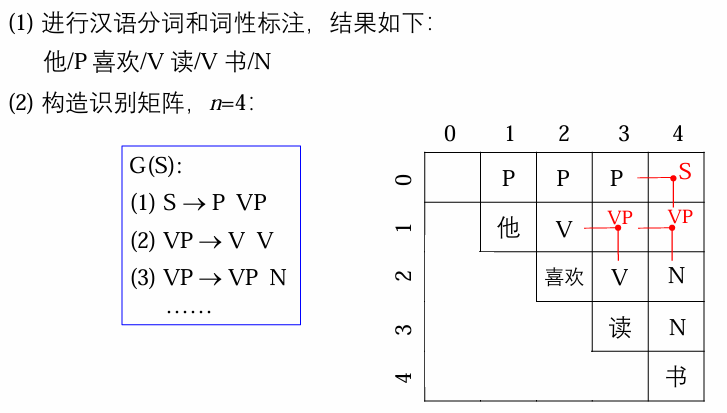
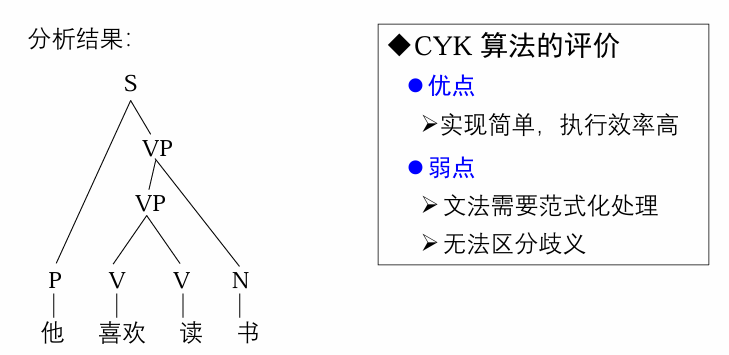
Coke-Younger-Kasami (CYK) 分析算法

算法描述:


例子:
概率上下文无关文法

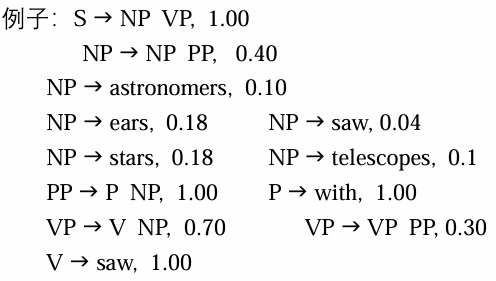
给定句子:Astronomers saw stars with ears.
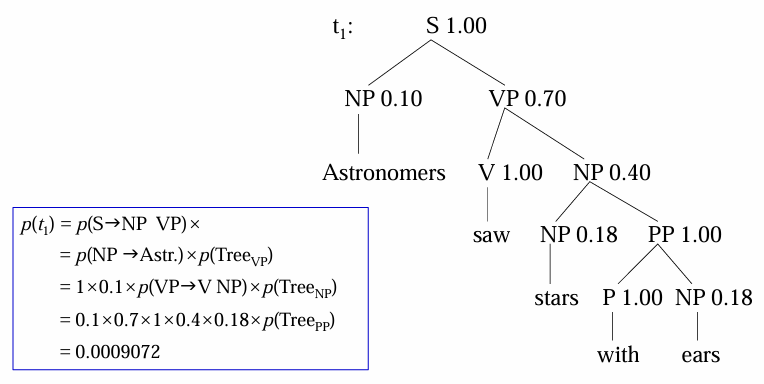
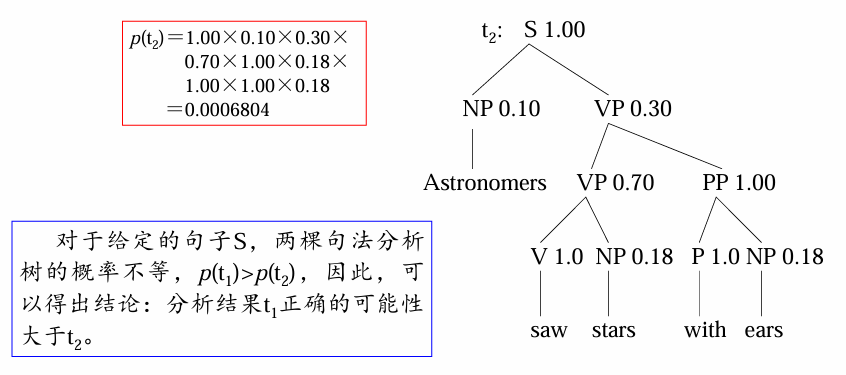
基于
- 优点:
- 可利用概率进行子树剪枝,减少分析过程的搜索空间,加快分析效率
- 可以定量地比较两个句法分析器的性能
- 弱点:分析树的概率计算条件比较苛刻,甚至不够合理
短语结构分析结果评价:
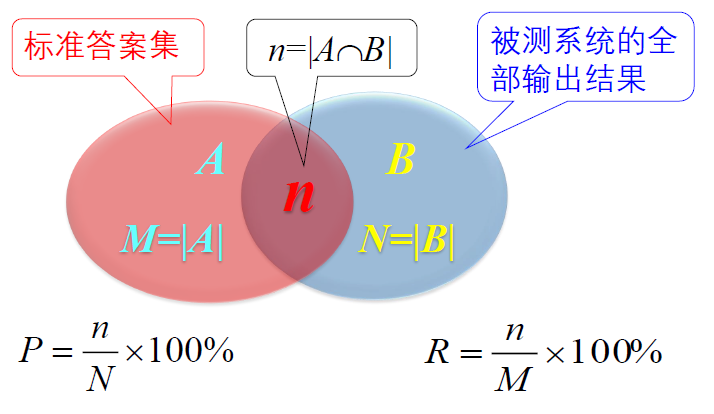
精度(precision):句法分析结果中正确的短语个数所占的比例,即分析结果中与标准分析树(答案)中的短语相匹配的个数占分析结果中所有短语个数的比例, 即:
召回率 (recall):句法分析结果中正确的短语个数占标准分析树中全部短语个数的比例,即:
F-measure:
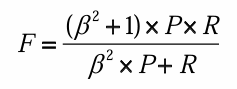
一般地,β = 1,称作
F1 测度 交叉括号数 (crossing brackets):一棵分析树中与其他分析树中边界相交叉的成分个 数的平均值。


分析树中除了词性标注符号以外的其他非终结符节点采用如下标记格式:XP
(起始位置:终止位置)。其中,XP

2. 依存关系分析
依存关系表示
两个有向图用带有方向的弧

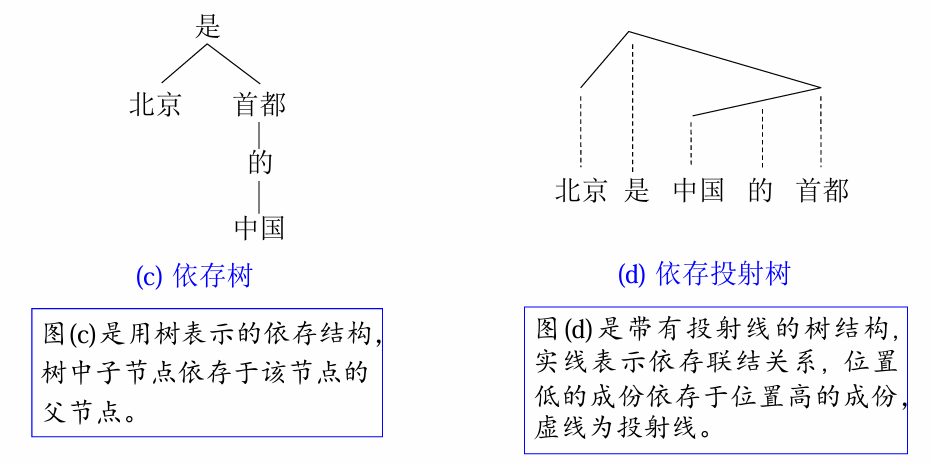
依存语法的四条公理
一个句子只有一个独立的成分;
句子的其他成分都从属于某一成分;
任何一成分都不能依存于两个或多个成分;
如果成分
A 直接从属于成分 B,而成分 C 在句子中位于 A 和 B 之间,那么,成分 C 或者从属于 A,或者从属于 B,或者从属于 A 和 B 之间的某一成分。
这
- 单一父结点
(single headed) - 连通
(connective) - 无环
(acyclic) - 可投射
(projective)
由此保证了句子的依存分析结果是一棵有
基本原则
- 谓语动词为句子的中心词
- 名词短语的中心词一般在右边;如果左边为人名、右边为称谓名词时,人名为中心词;
- 数量词短语中数字为中心词;
- 动词短语的中心词为动词;
- 介词短语的中心词为介词;
- 连词短语的中心词为连词;
- “的”
字结构的中心词为 “的”。
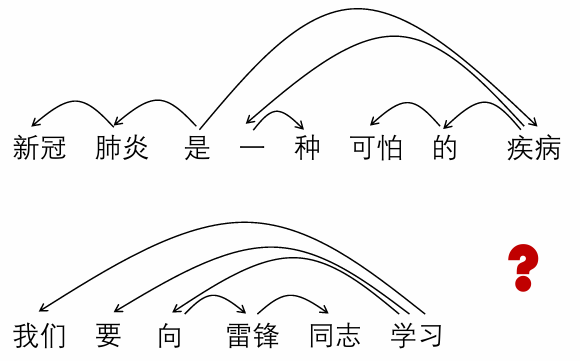
依存关系分析方法概览

决策式
基本思想
:模仿人的认知过程,按照特定方向每次读入一个词,每次都要根据当前状态做出决策,如判断当前读入的词是否与前一个词发生依存关系。一旦做出决策,之后不再改变。所谓的决策就是
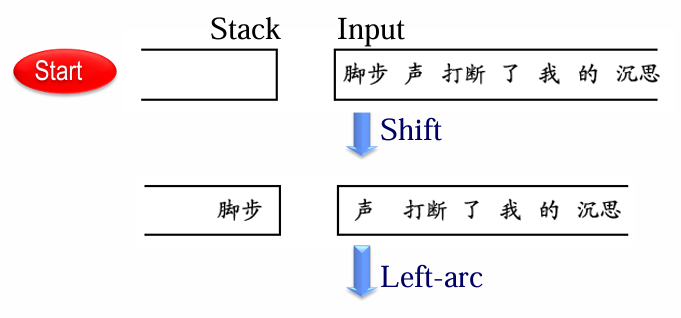
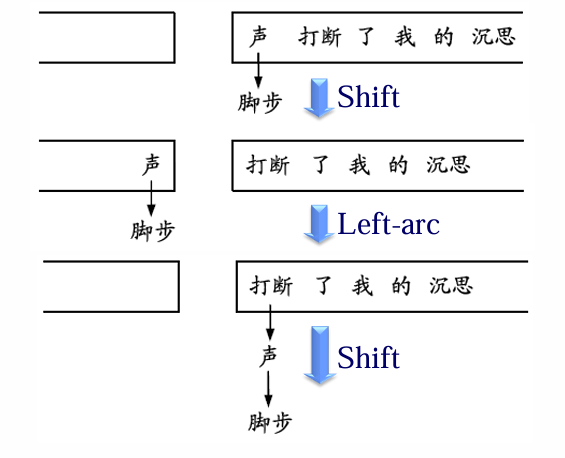
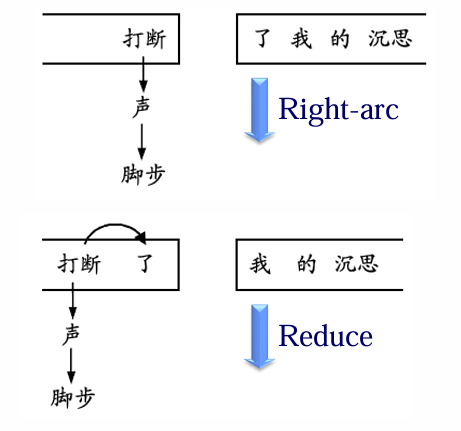
移进-归约算法
4 种操作
Arc-eager 分析算法:

举例:给定如下句子:脚步 声 打断 了 我 的 沉思
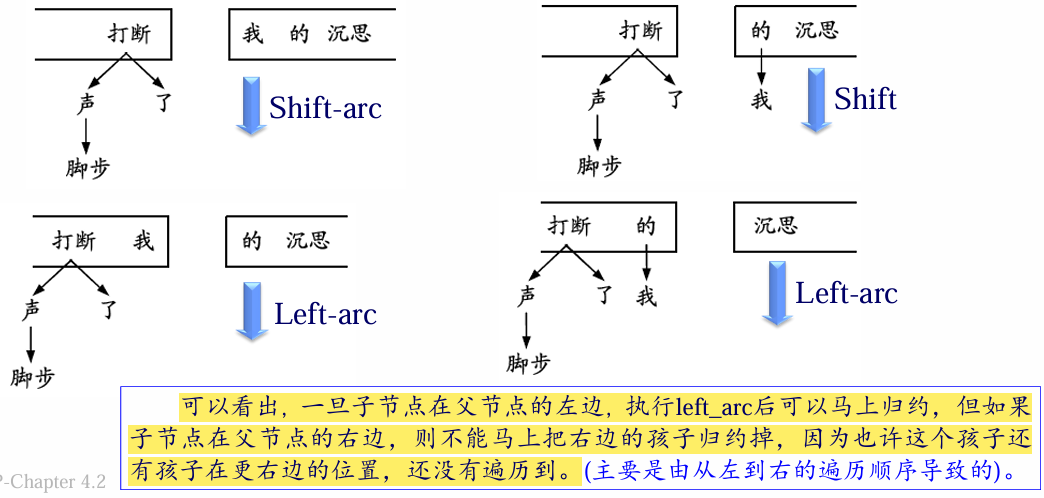
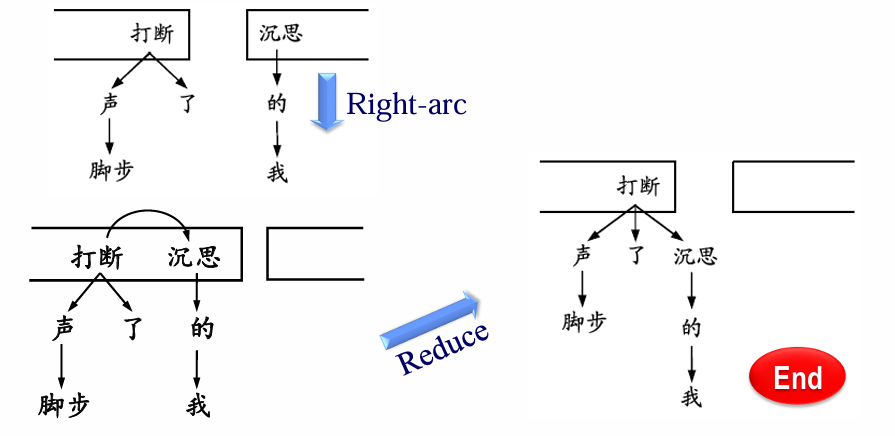

依存关系分析结果评价
- 无标记依存正确率
(unlabeled attachment score, UA 或 UAS):所有词中找到其正确支配词的词所占的百分比,没有找到支配词的词 (即根结点) 也算在内。 - 带标记依存正确率
(labeled attachment score, LA 或 LAS):所有词中找到其正确支配词并且依存关系类型也标注正确的词所占的百分比,根结点也算在内。 - 依存正确率
(dependency accuracy, DA): 所有非根结点词中找到其正确支配词的词所占的百分比。
4.3 语义分析
1.
- 目标与任务:解释自然语言的句子或篇章各部分
(词、词组、句子、段落、篇章) 的含义。 - 面临的困难:
- 句子中存在大量的歧义,涉及指代、同义
/ 多义、量词的辖域、隐喻等; - 语境相关性:同一个句子在不同的语境下可能有不同的含义;
- 语义的表示方法
- 人脑对语义理解的认知过程尚不清楚,语义计算的理论、方法和模型尚未建立。
- 句子中存在大量的歧义,涉及指代、同义
2.
语义网络通过由实体、概念或动作、状态及语义关系组成的有向图来表达知识、描述语义。
- 有向图:图的结点表示实体或概念,图的边表示实体或概念之间的关系。
- 边的类型:
- 是一种抽象
(IS-A):A 到 B 的边表示 “A 是 B 的一种特例”; - 是一部分
(PART-OF):A 到 B 的边表示 “A 是 B 的一部分”; - 是属性
(IS):A 到 B 的边表示 “A 是 B 的一种属性”; - 拥有
/ 占用 (HAVE):A 到 B 的边表示 “A 拥有 B”; - 次序在先
/ 前 (BEFORE):A 到 B 的边表示 “A 在 B 之前”;
- 是一种抽象
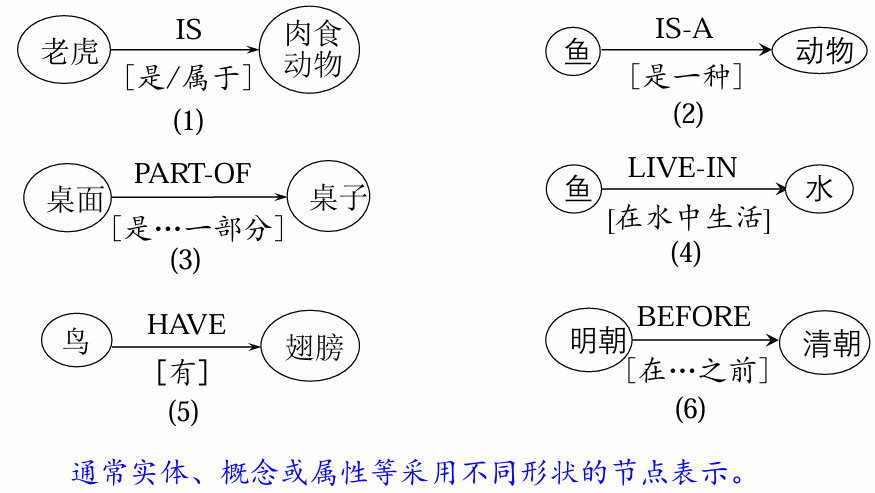
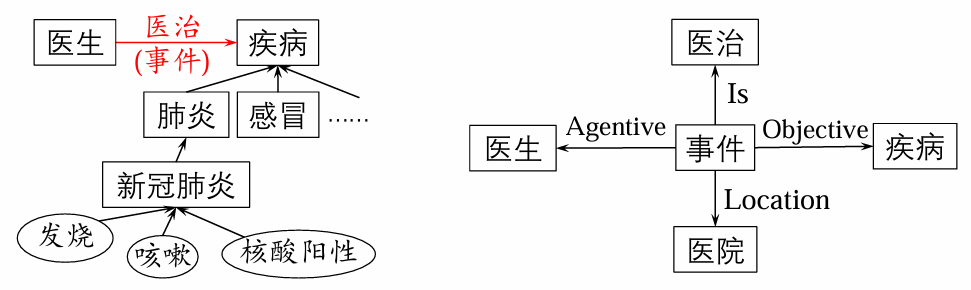
当语义网络表示事件时,结点之间的关系可以是施事、受事、时间等。这里所说的
例如:张三帮助李四。
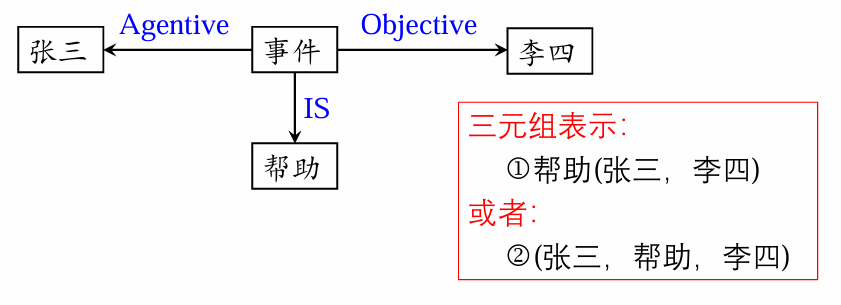
事件的语义表示
- 分类关系:事物之间的类属关系。
- 聚焦关系:多个下位概念构成一个上位概念。
- 推论关系:由一个概念推出另一个概念。
- 时间、位置关系:事实发生或存在的时间、位置。
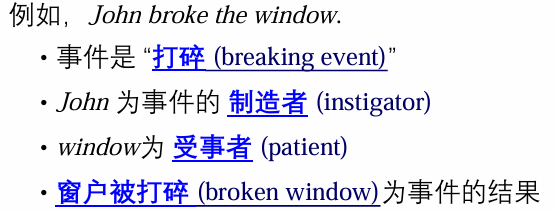
3.
自动语义角色标注

动词命题库
起初是在 Upenn 英语树库
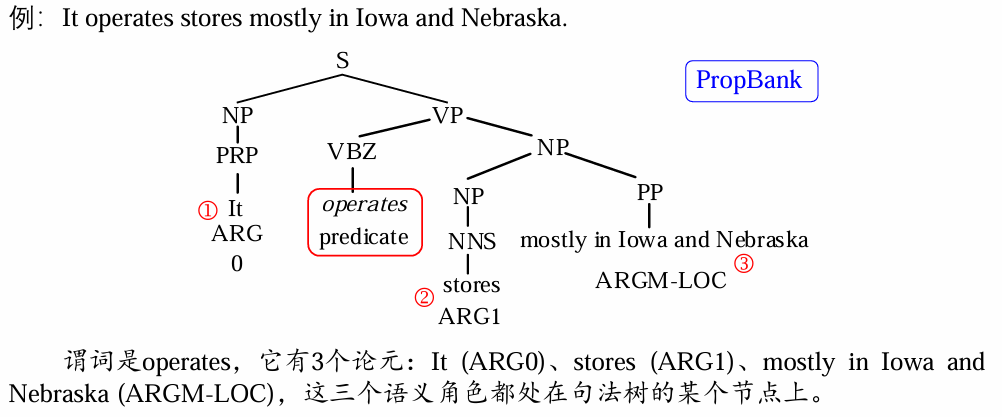


SRL
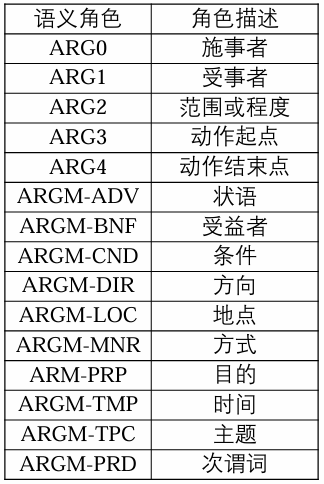
- 与具体谓词直接相关的,这些角色用
ARG0,ARG1,…,ARG5 表示,如 ARG0 通常表示动作的施事者,ARG1 表示动作的影响 (受事者 / 宾语 (object)) 等,ARG2-ARG5 对于不同的谓语动词会有不同的语义含义; - 起修饰作用的辅助性角色,其角色标签都以
ARGM 开头,常见的有表示时间的角色 ARGM-TMP,表示地理位置的角色 ARGM-LOC,表示一般性修饰成分的角色 ARGM-ADV 等。
中文语义角色标注的语料库主要有
基于短语结构树的
候选论元剪枝
将谓词作为当前节点,依次考察它的兄弟节点:如果一个兄弟节点和当前节点在句法结构上不是并列的
(coordinated) 关系,则将它作为候选项。 如果该兄弟节点的句法标签是 PP(介词短语),则将它所有的子节点也都作为候选项。 将当前节点的父节点设为当前节点,重复第
1 步的操作,直至当前节点是句法树的根节点。 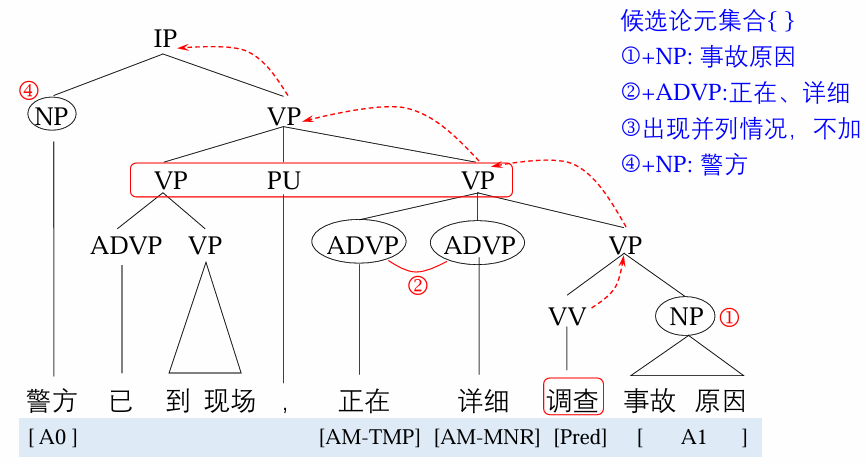
论元识别和标注
- 论元识别和标注看作一个分类 问题,在这一阶段最重要的工作
是为分类器选择有效的特征。常 用的一些有效特征有:
- 谓词本身
- 路径
(path): 句法树上从论元到谓词的路径, 如上面图中的 A0 论元到谓词的路径就是:NP↑IP↓VP↓VP ↓VP↓VV - 短语类型
(phrasetype): 论元所对应的句法树节点的句法标签 - 位置
(position): 论元出现在谓词之前还是之后 - 语态
(Voice): 谓词是主动语态还是被动语态 - 中心词
(HeadWord): 论元的中心词及其词性 - 从属类别
(Sub-categorization): 展开谓词父节点的上下文无关规则,如前面图中谓词的从属类别就是 VP→ADVP ADVPVP - 论元的第一个和最后一个词
- 组合特征
(Combination features): 谓词+中心词,谓词 + 短语类型等。
- 论元识别和标注看作一个分类 问题,在这一阶段最重要的工作
是为分类器选择有效的特征。常 用的一些有效特征有:
分类器:贝叶斯、最大熵、SVM、感知机等。
基于依存关系的
与基于短语结构句法分析的
SRL 方法的区别在于:基于短语结构句法分析的语义角色标注方法中,一个论元被表示为连续的几个词(短语)和一个语义角色标签。而在基于依存句法分析的语义角色标注中, 一个论元被表示为一个中心词和一个语义角色标签。因此,在这种方法中,谓词论元关系可以表示为谓词与论元的中心词之间的关系。 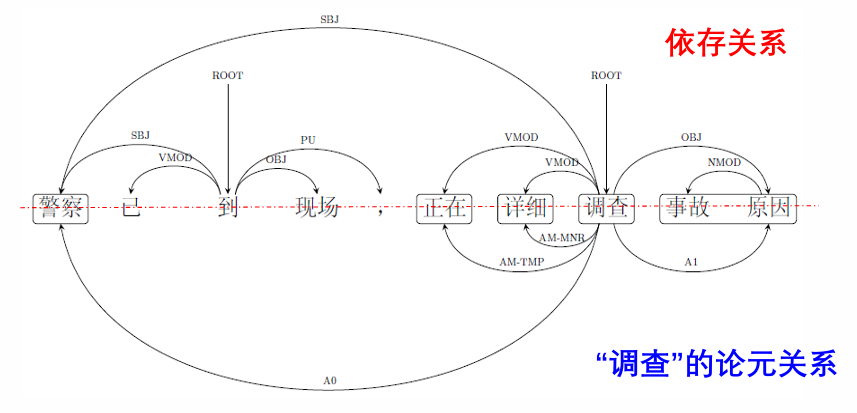
实现方法
确定候选论元
将谓词作为当前节点,将它所有的孩子都作为候选项;
将当前节点设为它的父节点,重复第
1 步的操作,直到当前节点是依存句法树的根节点。 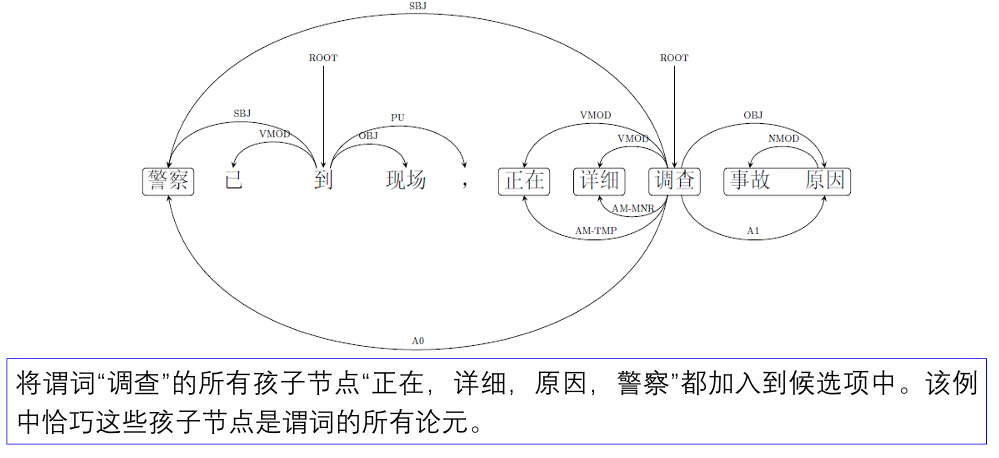
论元的识别和标注:从上述过程可以看出,基于依存句法的语义角色标注最终都是在判断谓词和候选的词之间的关系。于是,无论是论元的识别还是论元的标注,其核心都是判断一对词之间的关系。论元识别和论元标注都被作为分类问题。几种最常用的特征包括:
- 谓词
(predicate): 谓词本身及其词根 - 谓词的词义:
谓词在语料中的词义类别 - 谓词词性
(predicate POS): 谓词的词性 - 谓词父节点的词及词性
- 谓词与其父节点之间的依存关系类别
- 依存关系路径
(relation path): 依存句法树上从候选词到谓词的路径;例如上图中 从 “事故” 到谓词的路径就是 NMOD↑OBJ↑ - 位置
(position): 论元出现在谓词之前还是之后 - 语态
(voice): 谓词是主动语态还是被动语态 - 从属类别
(dependency sub-categorization): 谓词的所有孩子对它的依存关系,如上图中谓词 “调查” 的依存从属类别是 SBJ_VMOD_VMOD_OBJ - 候选词本身
- 候选词最左边和最右边的孩子的词与词性
- 候选词左边和右边最近的兄弟的词与词性
- 谓词
分类器:贝叶斯、最大熵、SVM、感知机等。
基于语块分析的
用语块分析
一般采用
不需要剪除候选论元,论元识别和标注同时进行。

第
1. 预训练的基本设置
大语言模型训练目标
不断以错误驱动方式调整词汇的语义表征和网络参数,使得模型能够正确预测下一个词语。


大语言模型训练设置
基于批次数据的训练设置
- 动态批次调整策略
- GPT-3 (175B):从
32K 个词元逐渐增加到 3.2M 个 - PaLM (540B):从
1M 个词元逐渐增加到 4M 个
- GPT-3 (175B):从
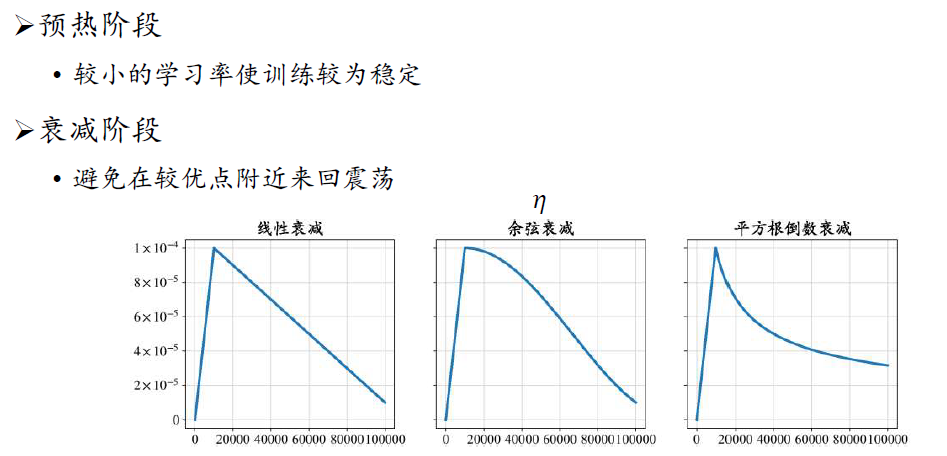
- 训练初期,较小批次使模型损失快速下降
- 训练后期,较大批次使模型损失稳定下降
大语言模型训练的优化器设置
- Adam
优化器 (Adaptive Moment Estimation) 使用动量作为参数更新方向:使用历史梯度的加权平均
自适应调整学习率:通过梯度的二阶矩对梯度进行修正

- Adafactor
优化器 - 更加节省训练显存
大语言模型训练的学习率设置
大语言模型训练稳定优化

2. 高效并行训练算法
分布式训练的数据通信基础
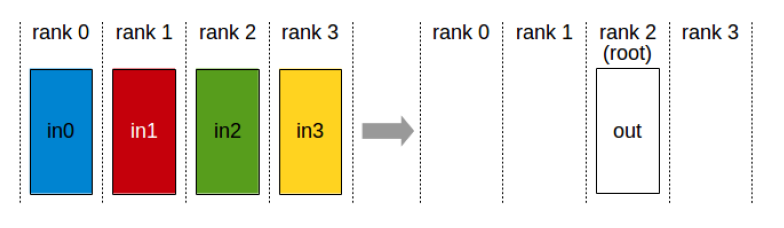
- 广播(broadcast)
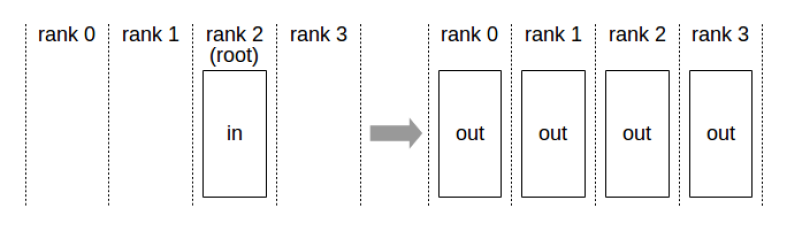
- 规约(reduce)
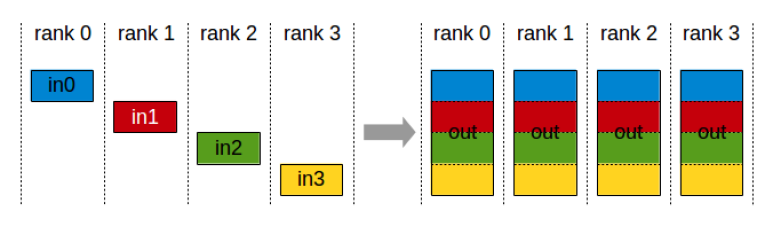
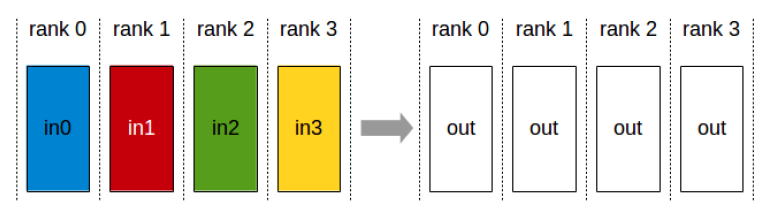
- 集聚(gather):每个进程都收集到所有其他进程的数据,最终每个进程都拥有一个由所有数据拼接而成的完整数据。
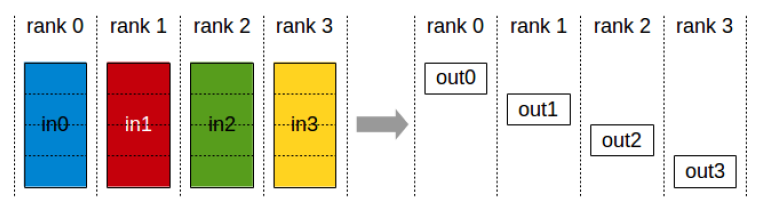
- 规约-散播(reduce scatter):首先对所有进程的对应位置数据进行 Reduce 操作(如求和、求最大值),然后将规约结果的不同部分分散给不同的进程。
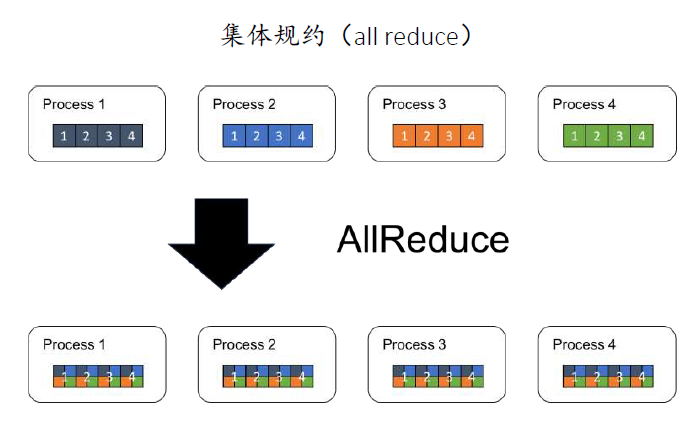
- 集体规约(all reduce):对所有进程的数据进行 Reduce 操作,并且让所有进程都得到一份相同的、完整的最终结果。
3D



1F1B


ZeroBubble


DualPipe


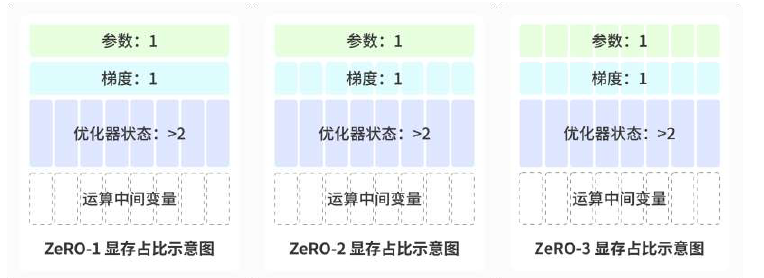
零冗余优化器(ZeRO)
ZeRO(Zero Redundancy Optimizer)-1/2:
- 基于数据并行,将优化器状态切分
- 同时优化中间量和优化器存储,计算量均摊
- 通信量与数据并行相当

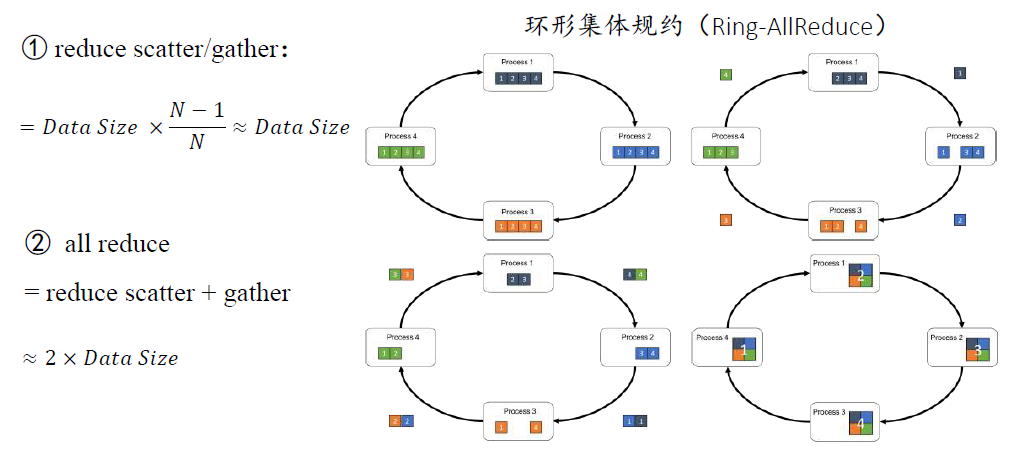
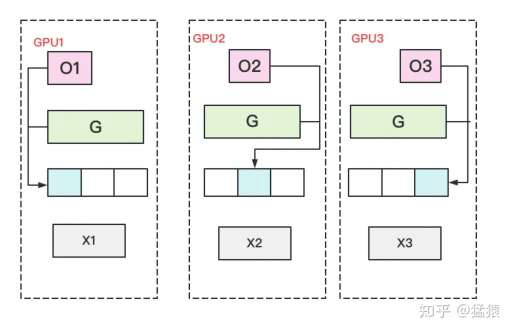
ZeRO-1:All-Reduce + All-Gather
- 每块
GPU 上存一份完整参数 W。将数据分成 3 份,每块 GPU 一份,做完一轮 foward 和 backward 后,各得一份梯度。 - 对梯度做一次
All-Reduce,得到完整的梯度 G。 - 得到完整梯度
G,就可以对 W 做更新。W 的更新由 optimizer states 和梯度共同决定。由于每块 GPU 上只保管部分 optimizer states,因此只能将相应的 W(蓝色部分)进行更新。 - 此时,每块
GPU 上都有部分 W 没有完成更新(图中白色部分)。所以我们需要对 W 做一次 All-Gather,从别的 GPU 上把更新好的部分 W 取回来。
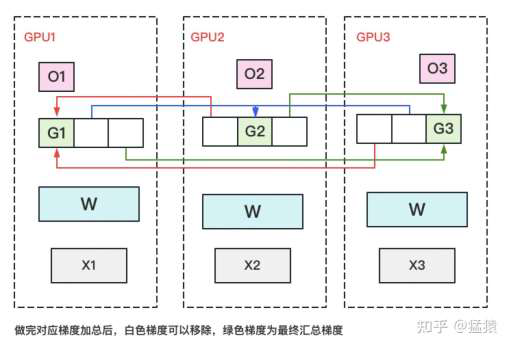
ZeRO-2:Reduce-Scatter + All-Gather
- 每块
GPU 上存一份完整参数 W。将数据分成 3 份,每块 GPU 一份,做完一轮 foward 和 backward 后,算得一份完整的梯度(图中绿色 + 白色)。 - 对梯度做一次
Reduce-Scatter,保证每个 GPU 上所维持的那块梯度是聚合梯度。例如对 GPU1,它负责维护 G1,因此其他的 GPU 只需要把 G1 对应的梯度发给 GPU1 做汇总。汇总完毕后,白色块对 GPU 无用,可以从显存中释放。 - 每块
GPU 用自己对应的 O 和 G 去更新相应的 W。更新完毕后,每块 GPU 维持了一块更新完毕的 W。同理,对 W 做一次 All-Gather,将别的 GPU 算好的 W 同步到自己这来。

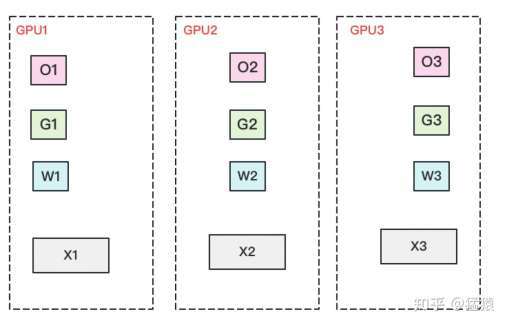
ZeRO-3:All-Gather + Reduce-Scatter
- 每块
GPU 保存部分参数 W,数据分成 3 份,每块 GPU 一份。 - 做
forward 时,对 W 做一次 All-Gather,取回分布在别的 GPU 上的 W,得到一份完整的 W,forward 做完,立刻释放不是自己维护的参数 W。 - 做
backward 时,对 W 做一次 All-Gather,取回完整的 W,backward 做完,立刻释放不是自己维护的参数 W。 - 做完
backward,算得一份完整的梯度 G,对 G 做一次 Reduce-Scatter,从别的 GPU 上聚合自己维护的那部分梯度,聚合操作结束后,立刻释放不是自己维护的 G。 - 用自己维护的
O 和 G,更新 W,无需对 W 做 All-Reduce 操作。
显存优化
卸载(Offloading)
- 前向计算时,将输入、输出、中间计算传输到内存上,释放中间计算结果,反向计算时再导入
- 多出的
CPU-GPU 的通信时间,通过计算通信的重叠来解决 - 通信换空间
激活重计算(Rematerialization)
- 释放中间过程的计算图,保留每层输出,反向求导时重新计算,计算换空间
- 算法的时间、空间上下界:
- 空间最优:空间复杂度
O(1),时间复杂度 O(N^2) - 额外进行一遍前向计算:空间复杂度
O(Sqrt(N)),时间复杂度 O(N)
- 空间最优:空间复杂度
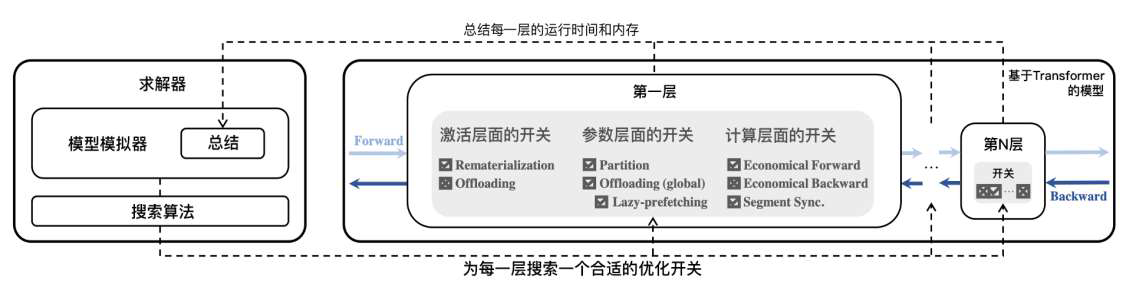
自动策略
- 高效训练深度神经网络需要综合使用并行策略、参数卸载、激活重计算的组合
- 使用动态规划求出最优的显存优化方案
- 可以与自动并行策略结合
混合精度训练
- 同时使用半精度浮点数(2
字节)和单精度浮点数(4 字节) - 前向传播
+ 反向传播:半精度 - 优化器中的模型参数副本:单精度
- 半精度浮点数
- FP16(1
符号位、5 指数位、10 尾数位):表示范围-65,504 到 65,504 - BF16(1
符号位、8 指数位、7 尾数位):表示范围达到 1038 数量级
- FP16(1


4.
参数量计算

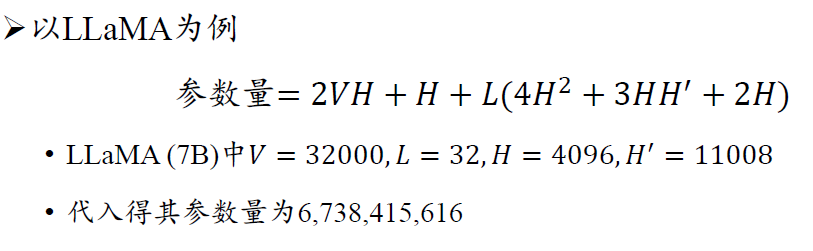
训练运算量估计



训练时间估计

训练显存估计






第
1. 训练数据来源
主要来源:
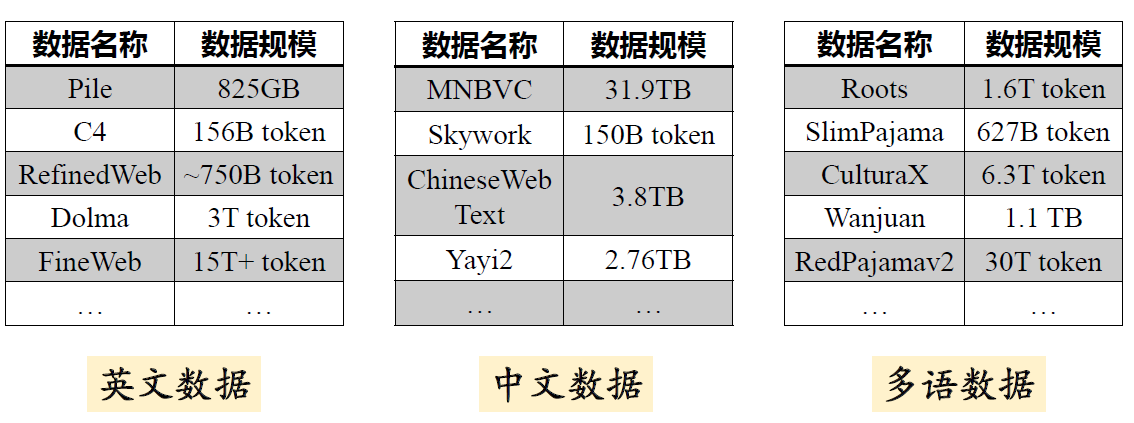
- 网页数据:Common Crawl (CC)
是最大的来源(约
500TB),但噪声大。 - 高质量数据:书籍、论文(ArXiv)、代码(GitHub)、维基百科。
- 开源数据集:C4, The Pile, Roots, RefinedWeb, RedPajama。
2023
年后的数据可能包含大量 AIGC 内容,需注意 “模型坍塌” 风险。
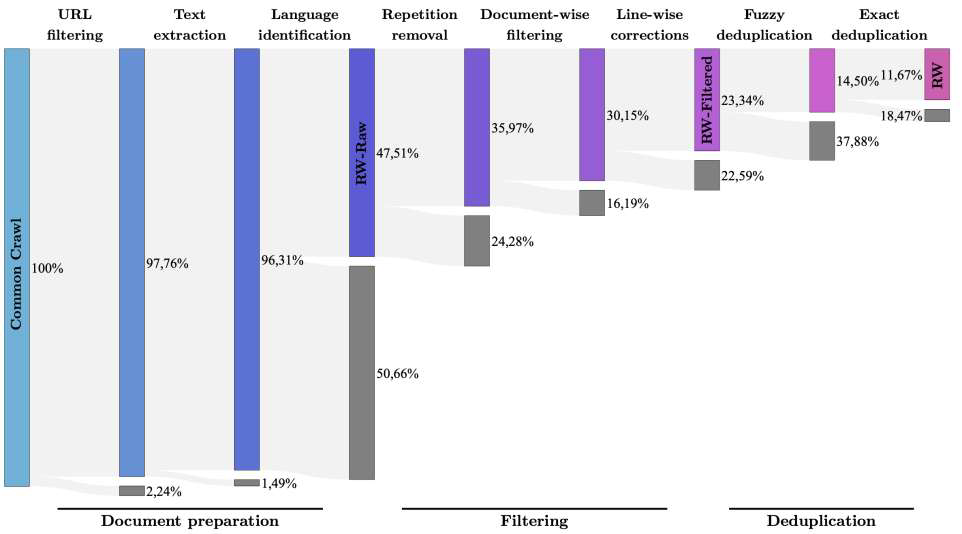
2. 训练数据处理方法
处理链路通常为:获取 -> 过滤 -> 去重 ->
隐私
质量过滤
- 启发式:基于规则(如标点符号比例、词汇数量、HTML
标签去除)。 - 基于分类器:训练
BERT 或 FastText 模型识别高质量文本(如参考 Wikipedia 风格)。
去重
- 重要性:重复数据会导致模型死记硬背,降低泛化能力。
- 方法:
- 精确匹配:URL
去重。 - 模糊匹配:MinHash + LSH (Locality Sensitive Hashing),用于发现相似但不完全相同的文档。
- 精确匹配:URL
词元化
核心问题:如何处理未登录词(OOV)和稀疏性。
主流算法:BPE (Byte-Pair Encoding)。
原理:从字符级开始,迭代合并频率最高的相邻字符对(Byte Pair),直到达到预设词表大小。
优势:平衡了字符级(太长)和单词级(太稀疏)的优缺点,具有高压缩率。


特殊处理:
- 数字:建议将数字按位切分(如
789->7, 8, 9),有助于数学推理。 - 代码:保留代码特有的缩进和符号结构。
- 数字:建议将数字按位切分(如
3. 训练数据配比方法
- 目标:平衡通用能力与领域能力。
- DoReMi
方法:使用一个小模型(Proxy Model)搜索最优的数据混合权重(Domain Weights),然后再用这个权重训练大模型。
第
预训练模型(Base
Model)只会
1. 指令微调
- 区别:
- Pre-training:学习世界知识,预测下一个词。
- SFT:学习指令遵循格式,泛化到未见过的任务。
- 数据构建:
- 人工标注:将
NLP 任务转化为 “Instruction + Input -> Output” 格式。 - Self-Instruct
(合成数据):利用强模型(如
GPT-4)生成多样化的指令和回复,再清洗(如 Alpaca)。
- 人工标注:将
- MoDS (数据筛选):不是数据越多越好。从质量(Quality)、覆盖度(Coverage)、必要性(Necessity)三个维度筛选少量高质量数据即可达到极佳效果。
2. 人类对齐
目标是让模型符合 HHH
- RLHF (Reinforcement Learning from Human Feedback)
三阶段:
- SFT (监督微调):训练一个基础的对话模型。
- RM (奖励模型训练):
- 人工对模型生成的多个回复进行排序(Ranking,如 A > B > C)。
- 训练
RM 模型预测这个排序得分(Pairwise Loss)。
- PPO (强化学习微调):
- 使用
RM 作为环境给予奖励。 - 优化策略 πθ 最大化奖励。
- 关键约束:加入 KL
散度 (KL Divergence) 惩罚项,防止模型偏离 SFT 模型太远(避免 “奖励模型欺骗”)。
- 使用
- DPO (Direct Preference Optimization) - 新趋势:
- 核心思想:跳过显式的奖励模型建模,直接在偏好数据上优化策略。
- 公式推导:将强化学习目标转换为一个分类损失函数,更加稳定且节省资源。
第
1. 基础提示
人工提示设计
关键要素
- 任务描述:使用关键词、特殊符号
(如###) 等

- 任务输入:适合大模型读取的格式
(文本序列、代码等)

- 上下文信息:检索文档、任务示例等

- 提示策略:特殊前后缀、拆分子任务等

设计原则
- 清晰地表达任务目标
- 分解为简单且详细的子任务
- 提供少样本示例
- 采用模型友好的提示格式
自动提示优化
离散提示优化
- 基于梯度的方法:使用梯度寻找合适的提示词
- 基于编辑的方法:编辑现有提示并观察模型性能
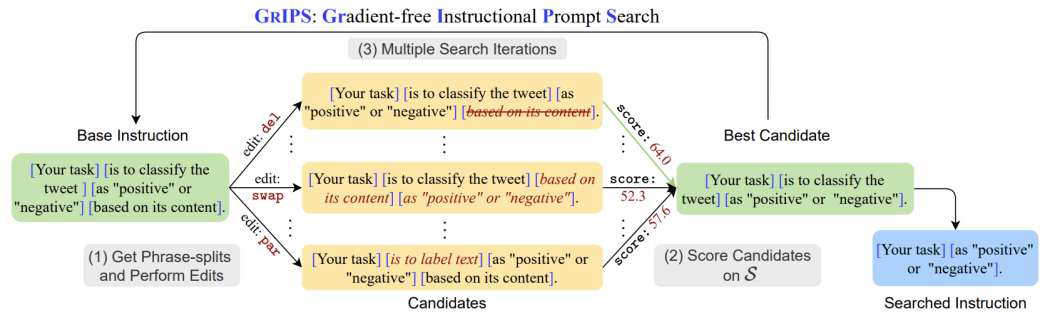
- 基于大语言模型的方法:利用上下文学习生成新提示
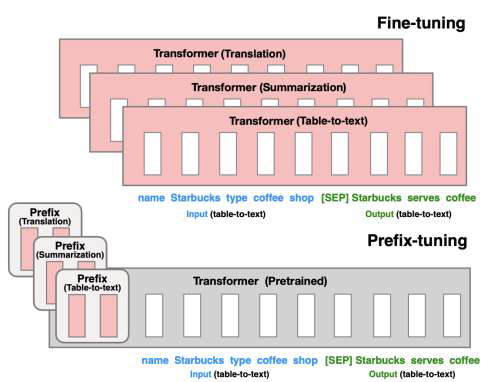
连续提示优化
监督学习方法
数据充足:提示向量作为可训练参数(prefix-tuning)
数据充足:提示向量作为可训练参数(p-tuning),在
Embedding 层将不重要的词语替换为可学习的连续向量 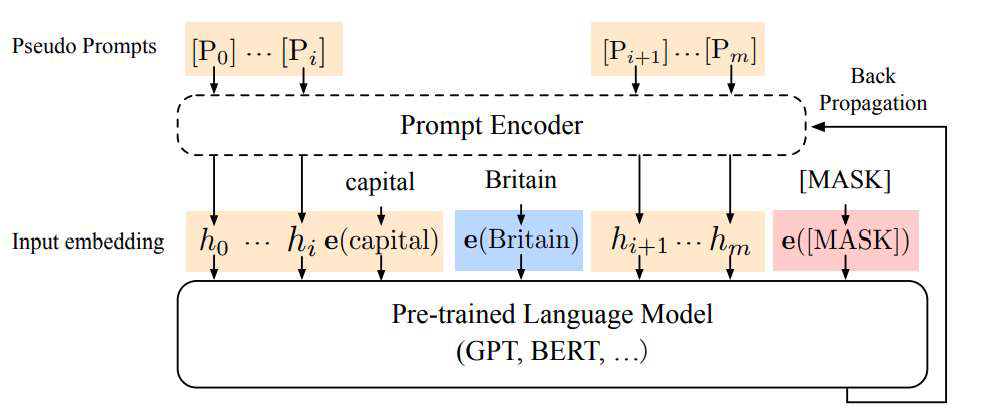
数据充足:提示向量作为可训练参数(prompt-tuning)

迁移学习方法:数据稀疏,其他任务提示初始化目标任务提示
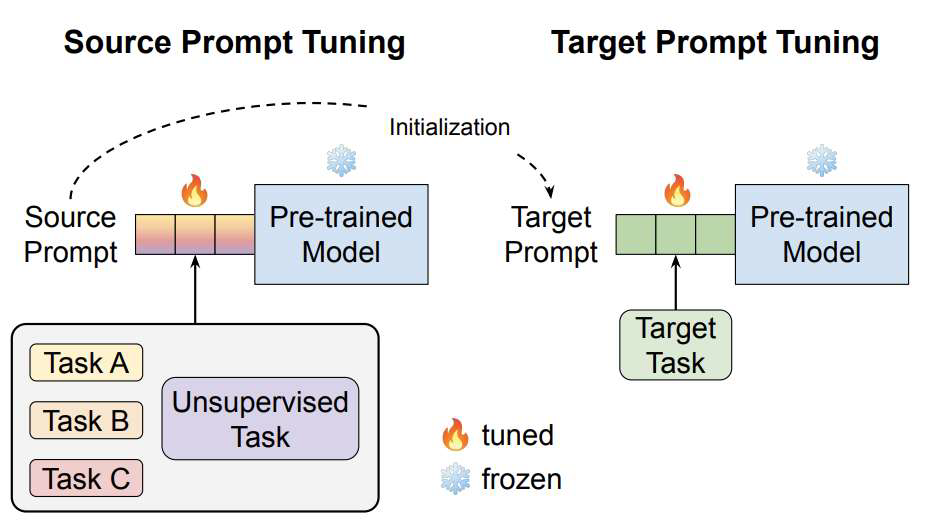
2. 上下文学习
形式化定义
- 上下文学习使用由任务描述和(或)示例所组成的自然语言文本作为提示
- 大语言模型无需显式的梯度更新即可识别和执行新的任务
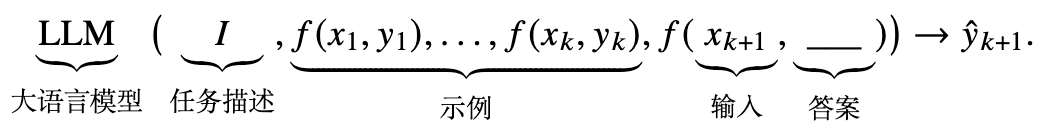
指令微调与上下文学习
- 共同点
- 都将任务转化为自然语言形式供大语言模型进行处理
- 不同点
- 指令微调:需要对大语言模型进行微调
- 上下文学习:仅通过提示的方式来调用大语言模型
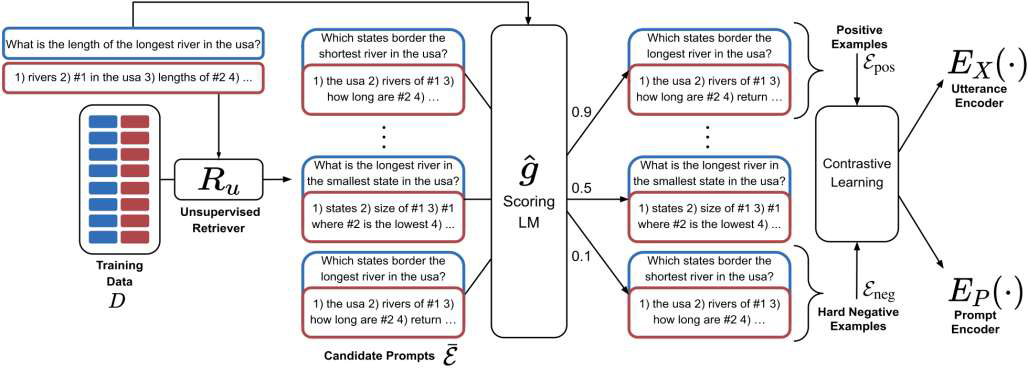
示例设计
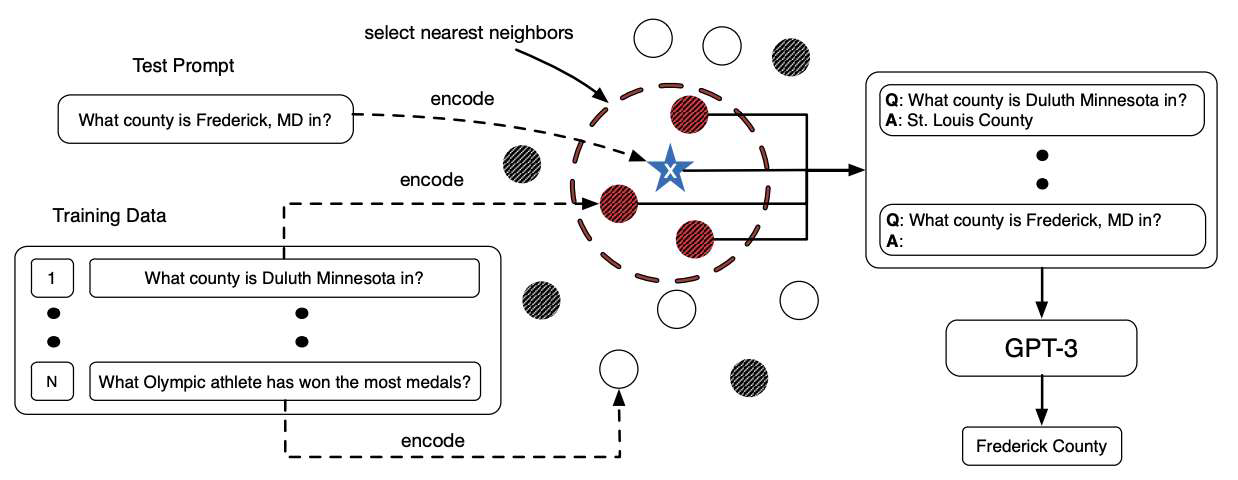
示例选择
- 基于相关度排序的方法
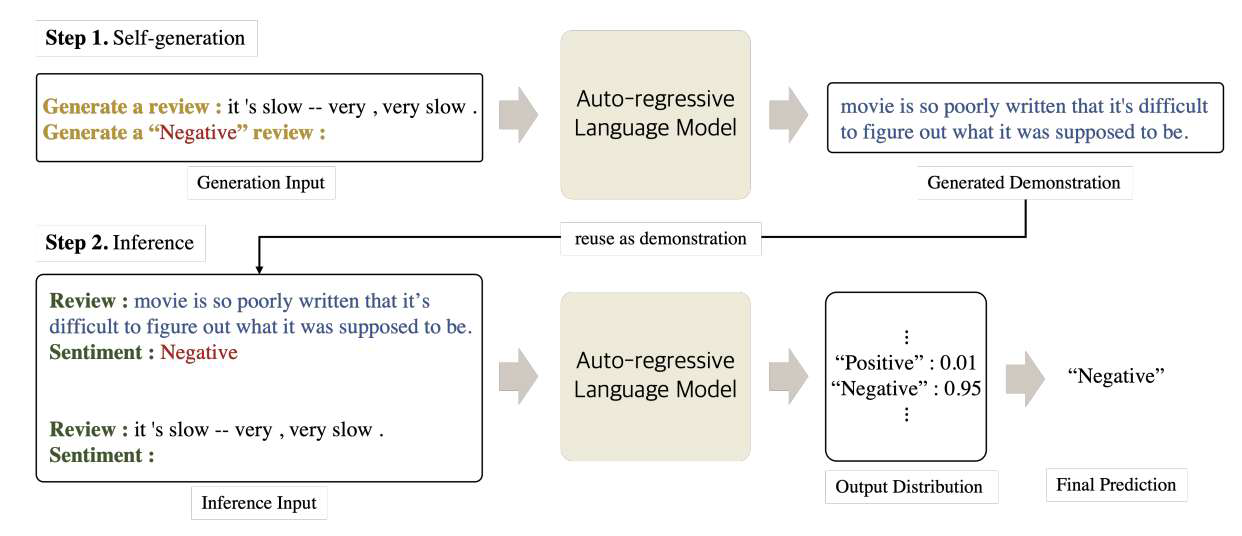
- 基于集合多样性的方法

- 基于大语言模型的方法
实例格式
- 人工标注的格式

示例顺序
- 产生候选示例顺序
- 评估示例顺序质量
底层机制
预训练阶段
预训练任务对上下文学习能力的影响:小规模的模型,通过设计专门的训练任务,进行继续预训练或微调,也能够获得上下文学习能力
预训练数据对上下文学习能力的影响:
- 预训练语料的多样性
- 预训练数据的长程依赖关系
- 高密度的低频长尾词汇
推理阶段
- 任务识别:从所提供示例中辨识当前任务的能力,利用预训练阶段所积累的丰富先验知识来解决任务,这个范式不受示例的输入和输出映射的影响。大语言模型具备从给定示例中学习并编码表征各种任务信息的隐变量的能力,在接收到新的输入时自动触发相应的任务识别过程。
- 任务学习:大语言模型还具备通过示例数据学习预训练阶段未涉及的新任务的能力。规模较小的模型已经能展现出较强的任务识别能力,较大规模的模型能展现出更强的任务学习能力。
3. 思维链
基本形式
- 是上下文学习的一种扩展:<输入,输出> => <输入,思维链,输出>
- 导出最终答案的一系列中间步骤
- 是一种能显著提升大模型在推理任务上表现的提示策略
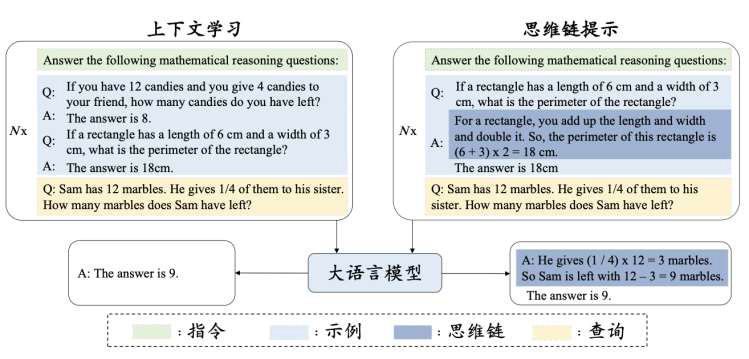
优化策略
针对输入端对大模型的思维链示例进行增强(思维链示例设计)
目前大语言模型在使用思维链提示进行推理时,大多采用了上下文学习的设定,即思维链提示通过示例的形式输入给大语言模型。
- 复杂化的思维链
- 思维链复杂度的量化指标:推理步骤的多少,思维链的长度,问题的长度
- 使用方式:在构造思维链提示时,选择那些带有更多推理步骤的样例作为提示,输入给模型
- 多样化的思维链
- 多样化的思维链示例可以为模型提供多种思考方式以及推理结构,从而得到正确的答案
- 使用方式:
- 使用聚类算法将训练集中的问题划分为𝑘个簇
(𝑘 为所需的示例数量) - 从每个簇中选择距离质心最近的问题作为代表性问题
- 将代表性问题输入给
LLM 并生成对应的思维链和答案 - 将
3 中的代表性问题、思维链、答案作为示例在测试集上使用
- 使用聚类算法将训练集中的问题划分为𝑘个簇
- 由于每个问题来自于不同的簇,从而保证示例的多样性
针对大模型的思维链生成过程进行改进(思维链生成方法)
模型在生成思维链时容易出现推理错误和生成结果不稳定等情况,因此除了改进思维链示例的设计之外,还需要对大语言模型生成思维链的过程进行改进
- 基于采样的方法
- 问题:大语言模型在使用单一的思维链进行推理时,一旦中间推理步骤出错,容易导致最终生成错误的答案。
- 解决方法:通过采样多条推理路径来缓解单一推理路径的不稳定问题
- 代表性方法:
- Self-consistency: 生成多条推理路径和对应的答案,然后基于这些答案进行集成(例如选择出现频率最高的答案)并获得最终的答案
- 基于验证的方法
- 问题:思维链提示所具有的顺序推理本质可能导致推理过程中出现错误传递或累积的现象
- 解决方法:使用专门训练的验证器或大语言模型自身来验证所生成的推理步骤的准确性
- 代表性方法:
- DIVERSE: 分别训练了针对整个推理路径(全局)和中间推理步骤(局部)的验证器,从不同的粒度实现更为全面的检查
针对整个思维链结构进行优化(拓展推理结构)
尽管基本的思维链提示具有广泛的适用性,但是所采用的链式推理结构在处理较为复杂的任务时
- 树推理结构
- 思维树的主要思想是将推理过程刻画为一个层次化的树结构,进而问题的求解就转化为在树上的搜索问题
- 树的每个节点对应一个思考步骤,父节点与子节点之间的连边表示从一个步骤进行下一个步骤
- 与思维链相比,思维链从一个节点出发,只能生成一个节点,而思维树则可以生成多个节点。当某一个思考步骤无法得到正确答案时,可以回溯到它的父节点,选择另一个子节点继续推理
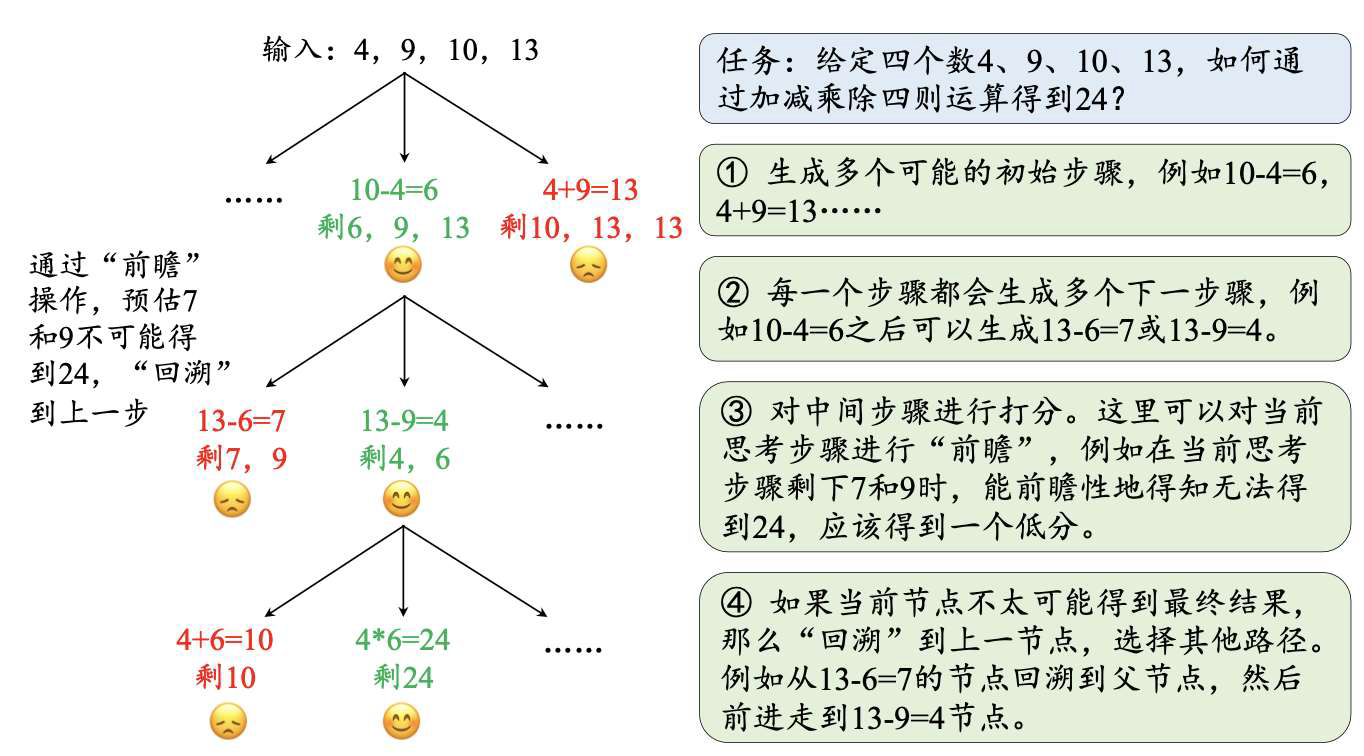
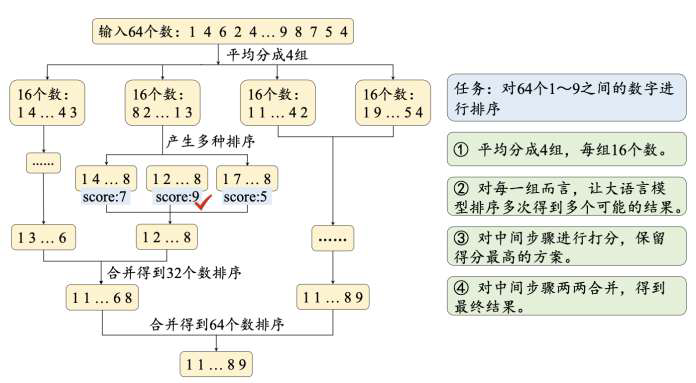
- 图推理结构
- 相较于树结构,图结构能够支持更为复杂的拓扑结构,从而刻画更加错综复杂的推理关系
- 思维图将整个推理过程抽象为图结构,其中的节点表示大语言模型的中间步骤,节点之间的连边表示这些步骤之间的依赖关系
- 与思维树相比,由于树结构中只有父节点和子节点之间有连边,因此无法构建不同子节点之间的联系。思维图则允许图上的任意节点相连,因此可以在生成新的中间步骤的同时考虑其他推理路径
思维链推理能力的来源
- 研究假设:思维链有效的原因是训练数据中存在相互重叠且互相影响的局部变量空间。
- 假设验证方法:构建具有链式结构的贝叶斯网络,合成包含相互影响的局部变量空间的训练样本。使用上述样本训练语言模型,通过给定一个变量来预测另一个变量的条件概率。
- 结果发现:
- 当两个变量不经常在数据中共现时,直接预测条件概率与真实概率存在一定偏差。
- 使用中间变量进行推理预测可以减小偏差。
- 当两个变量经常在数据中共现时,通过中间变量推理和直接预测带来的偏差较接近。
- 函数学习角度的研究:复杂推理任务可以视为组合函数,思维链推理将学习过程分解为信息聚焦和上下文学习两个阶段。
- 第一阶段:语言模型隐式地聚焦于思维链提示中与推理的中间步骤相关的信息。
- 第二阶段:基于聚焦得到的提示,语言模型通过上下文学习输出一个推理步骤(单步组合函数的解),并逐步进行下一步推理,以获取最终答案(整个组合函数的最终解)。
- 理论与实验证明:信息聚焦阶段显著减少了上下文学习的复杂度,只需关注与推理相关的重要信息;而上下文学习阶段促进了复杂组合函数的学习,标准提示很难让模型学习到这种复杂函数。
思维链提示对模型推理的影响
- 思维链
= 符号(例如数学题中的数字、常识问答中的实体)+ 模式(例如数学题中的算式、常识问答中的句子结构和模板) - 实验发现:思维链示例中算式的正确与否不会显著影响模型的性能
- 结论:符号和模式的目的都是表达任务意图,具体的内容不重要,重要的是它们与问题的相关性以及推理过程的逻辑性
- 即使不对语言模型使用思维链提示,只要其生成的文本中包含显式的推理过程,也能显著改善模型的推理能力。
- 这表明,思维链提示通过激发模型生成中间推理步骤来提高其生成正确答案的概率
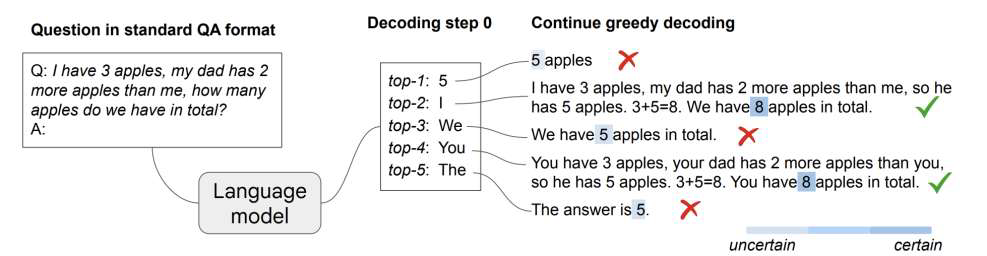
第
1. 多语言大模型背景
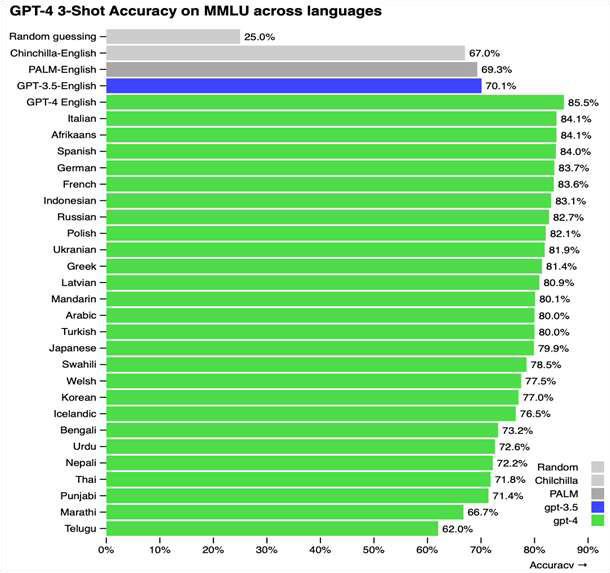
随着模型尺寸、数据规模的不断增长,大语言模型的能力越来越强。但是绝大多数大语言模型聚焦英文、中文等主流资源丰富语种,经常忽略对其他语言(尤其是低资源语言)的友好支持。例如
2. 多语言大模型方法
多语言大模型框架
解码器框架:XGLM
- 优化目标:因果语言模型,下一个词语预测模型
- 模型规模:7.5B
- 训练数据:30
种语言,500Btokens
解码器框架:BLOOM
- 优化目标:因果语言模型,下一个词语预测模型
- 模型规模:176B
- 训练数据:46
种语言,366Btokens
解码器框架:Qwen
- 优化目标:因果语言模型,下一个词语预测模型
- 模型规模:Qwen3–0.6/1.7/4/8/14/32/235B
- 训练数据:119
种语言,36Ttokens
解码器框架:LLaMA
LLaMA 3:
- 优化目标:因果语言模型,下一个词语预测模型
- 模型规模:LLaMA3-8B、70B
- 训练数据:>30
种语言,15Ttokens
LLaMA 4:
- 优化目标:因果语言模型,下一个词语预测模型
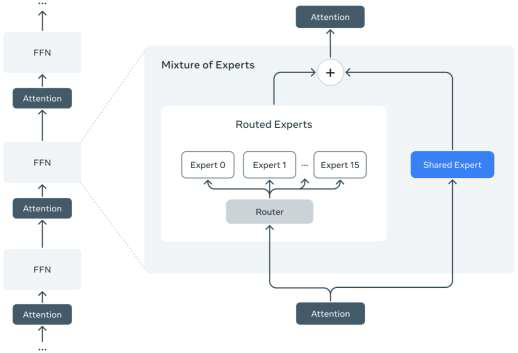
- 模型架构:专家混合系统
MoE - 模型规模:LLaMA4-109B、400B、2T
- 训练数据:200
种语言,30Ttokens
多语言大模型训练
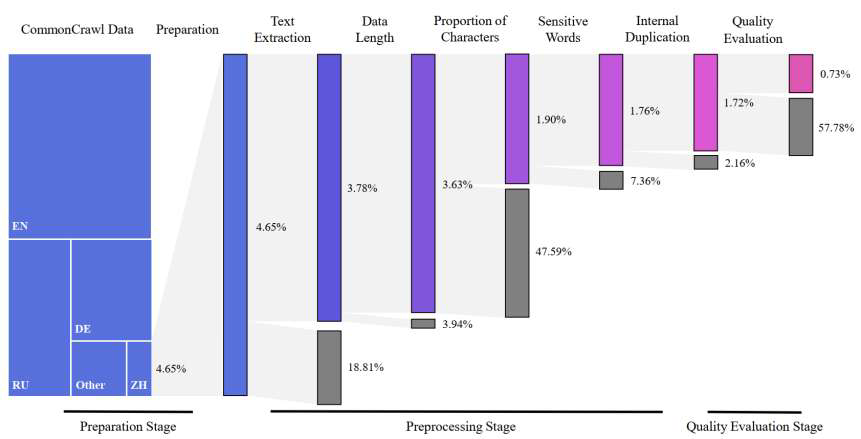
多语言数据来源
多语言数据清洗
英文
中文
最终的高质量中文数据只占原始数据的
多语言训练策略
- 多语言数据混合训练:
- 将所有语言数据合并,视为一种语言的数据进行训练
- 按照不同语言的数据比例,进行采样训练,对资源稀缺语言进行平衡采样
- 多阶段训练方法:
- 首先:高资源语言训练,例如中英文能力训练(e.g.80%tokens)
- 其次:高资源语言专业能力训练,例如中英文数学、代码训练
(e.g.5%tokens) - 最后:多语言能力训练,例如所有语言数据混合训练(e.g.5%tokens)
多语言大模型对齐
- 指令微调:
- 目标:
- 与用户意图对齐
- 生成人类偏好的回复
- 数据:高质量指令遵循样例
- 人工标注
- 从
GPT-4 等更强的模型中蒸馏
- 目标:
多语言指令数据构造
现状:低资源语言能力较弱:(1)容易生成不安全回复;(2)忽略语言特性。
解决方案:构造更好的多语言指令数据
- 人工构造:很多低资源语言无法找到合适的标注者,代价高昂
- 蒸馏方法:教师模型在很多低资源语言上也表现不佳
- 翻译方法:翻译错误、忽略特定语言现象和细节
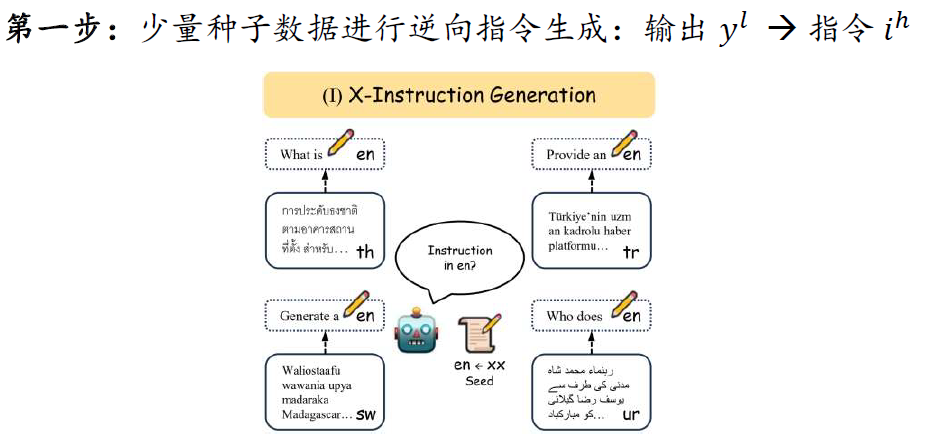
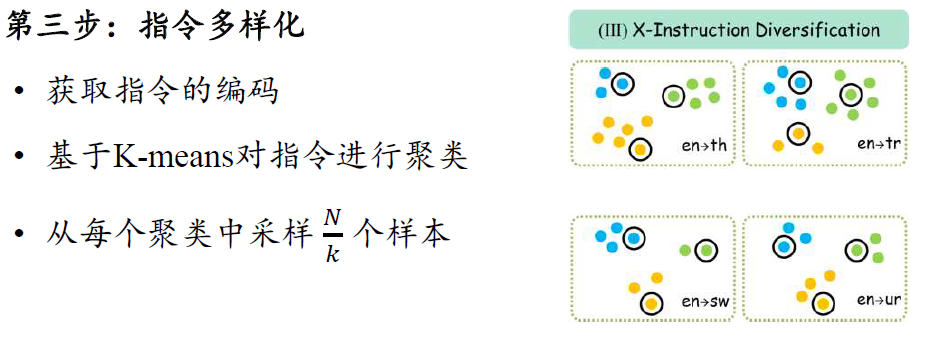
提升低资源语言能力
基于少量双语平行数据,利用多语言对比学习和跨语言指令学习,显著提升大模型在低资源语言、零资源语言上的能力。
低资源高质量指令数据的逆向生成:回复是低资源语言,指令是英文。

3. 多模态大模型背景
现实物理世界中有文本、视觉、音频、3D、雷达、多谱等复杂多样的不同模态信号。
- 大语言模型:以语言文本为训练数据,以
NextWordPrediction 为优化目标的大模型,例如 GPT-4、DeepSeek、Claude 等。 - 特点:可实现多语言内容生成、代码生成等;具有一定的认知推理能力;应用受限于语言模态。
- 图文大模型:基于图文两模态数据,通过对比学习或图文生成训练,产生图文理解与生成的大模型,例如
CLIP、DALL-E 等。 - 特点:可实现精细的文生图、图生文等功能;创造性更强的同时幻觉问题更严重。
- 多模态模型:以大语言模型为认知基座,将其他各种模态对齐到语言空间,实现多模态大模型,例如
LLaVA、GPT-4o、Gemini-3 等。 - 特点:可实现多种模态之间各种模态的相互转换和生成;应用场景更加广泛;幻觉问题更加突出。
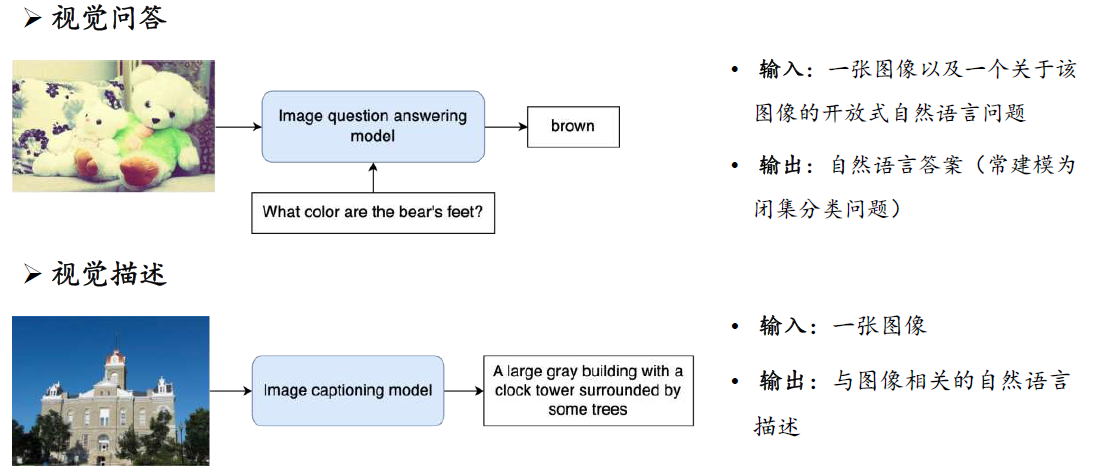
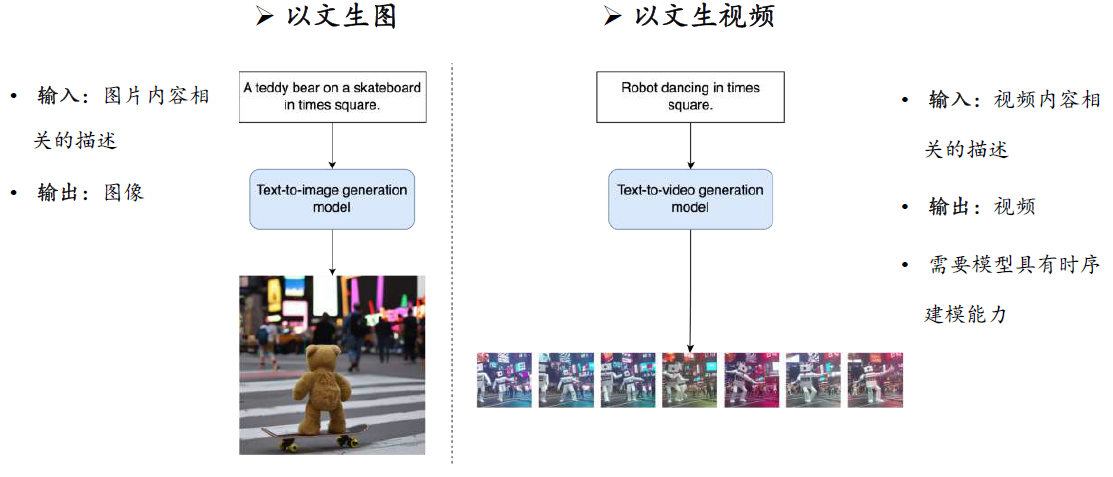
多模态下游任务


4.
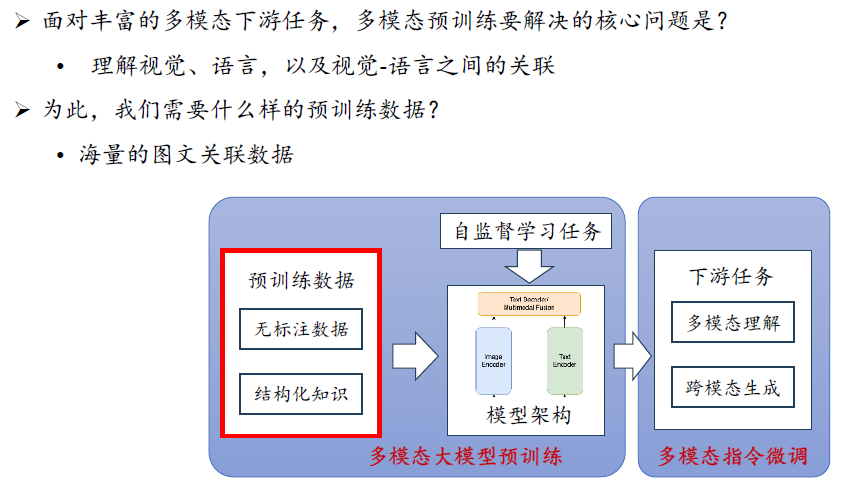
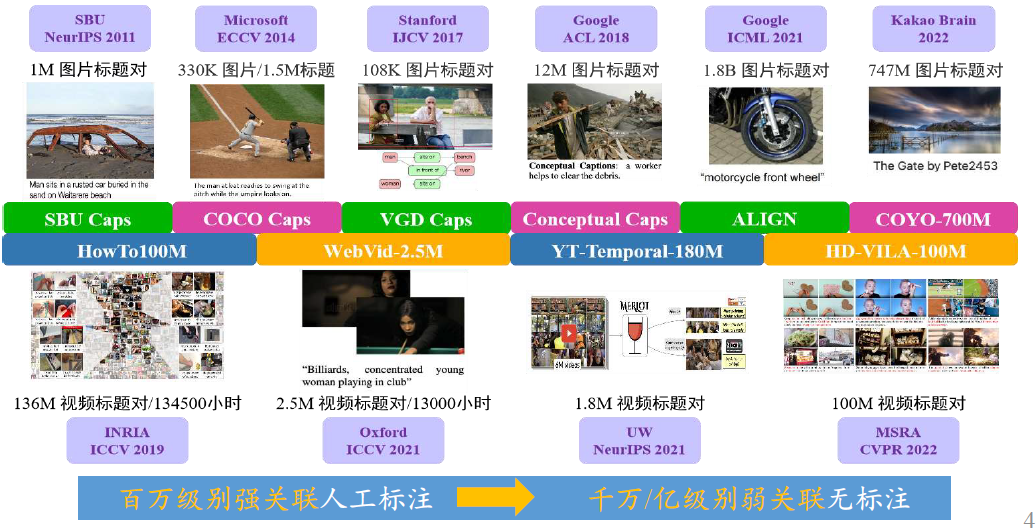
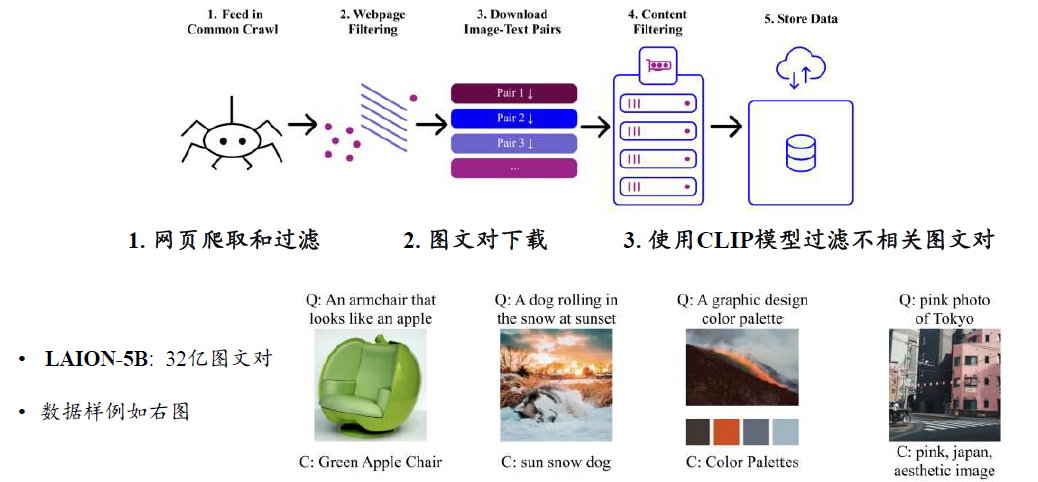
多模态大模型预训练数据
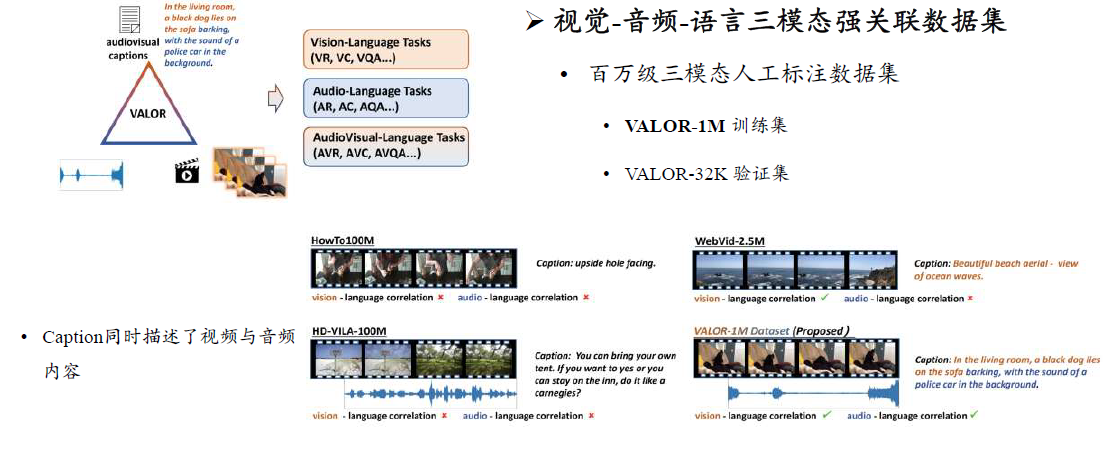
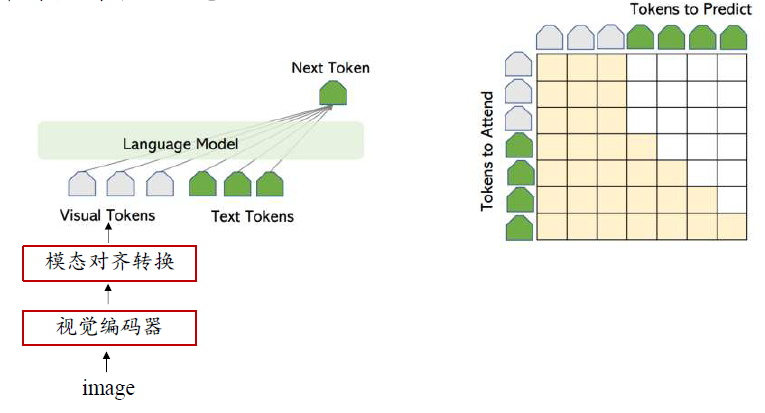
多模态大模型架构
大多以大语言模型为中心的架构,核心在于如何将其他模态对齐转换到语言模态
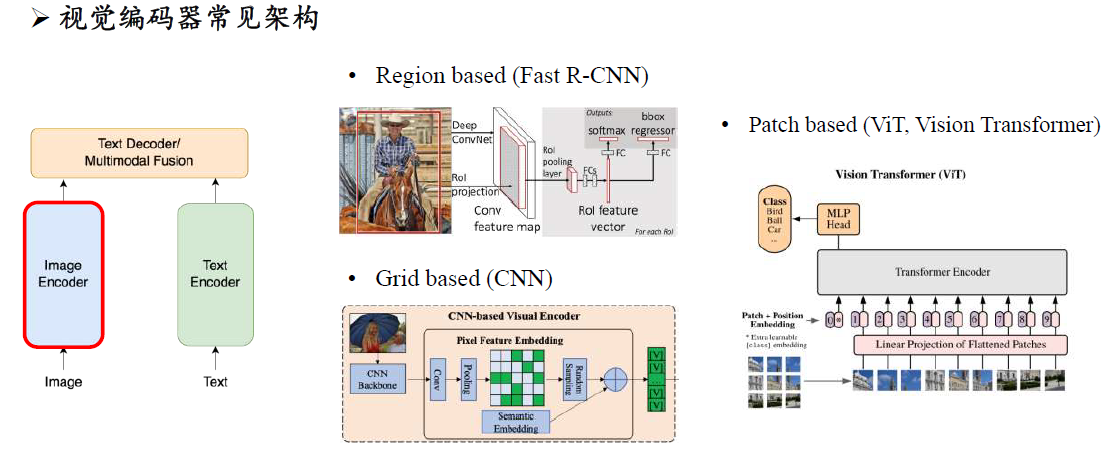
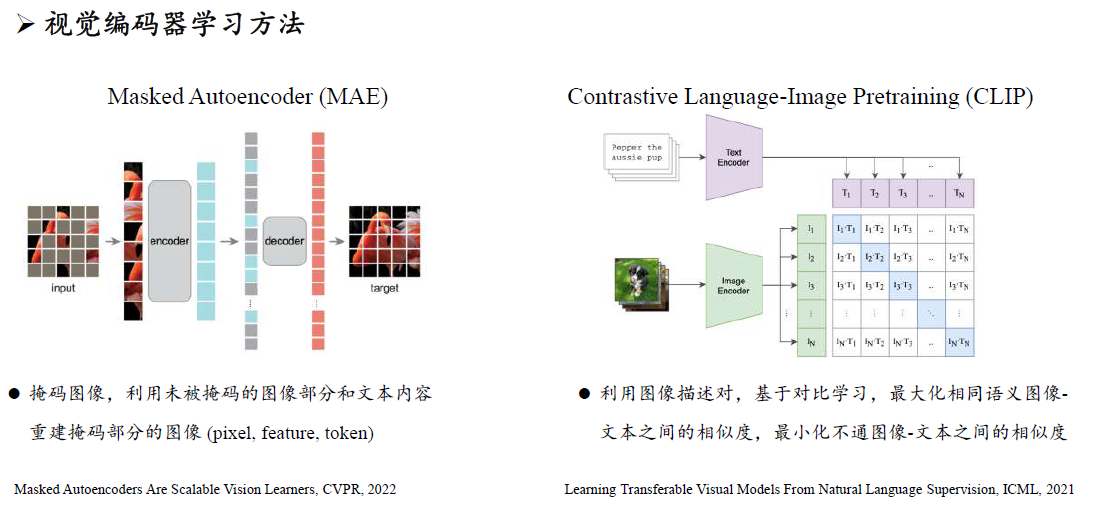

多模态指令微调

多模态指令数据构造
- 从已有数据集中提取图像-文本对(CC、LAION);
- 使用图像
caption 和物体边界框信息将图像编码为 LLM 可识别的序列; - 利用
GPT-4 生成三种类型的指令数据:对话、详细描述和复杂推理。

多模态指令微调方法
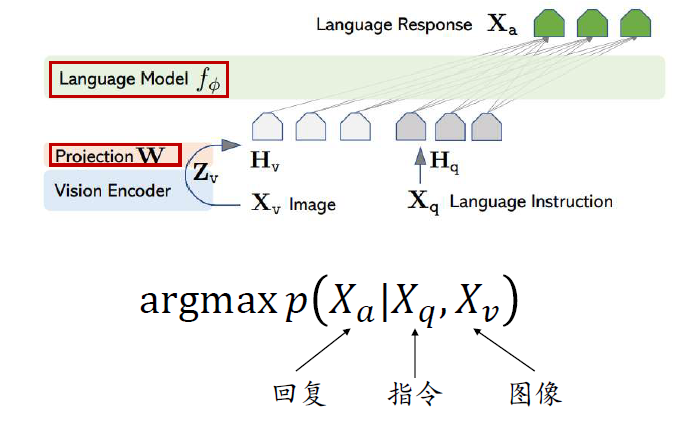

第
1. 背景介绍
大语言模型的幻觉问题
- 语境冲突性幻觉(忠实性幻觉):LLM
生成的内容与之前生成的信息本身相冲突,或 LLM 生成的内容与用户提供的输入相背离。 - 与事实相冲突的幻觉:即
LLM 生成的内容不忠实于既定的世界知识。
幻觉产生原因
- 大模型缺乏相关知识或内化错误知识(来自于数据)
- 将相关性(如位置接近或高度共现的关联)误解为事实知识
- LLM
偏向于肯定测试样本,容易复制甚至放大这种幻觉行为 - 存在一些导致幻觉的训练数据(模仿性、重复性、社会偏见、知识边界或过时等)
- 大模型有时会高估自己的能力
- 对于超大
LLM 来说,正确答案和错误答案的分布熵可能是相似的 - LLM
在生成错误答案时与生成正确答案时同样自信
- 对于超大
- 有问题的对齐过程可能会误导大模型产生幻觉
- 如果
LLM 在预训练阶段没有获得相关的先决知识,在训练指令时是一个错误的对齐过程,会促使 LLM 产生幻觉 - “谄媚”(sycophancy),LLM
可能会生成偏向用户观点的回答,而不是提供正确或真实的答案
- 如果
- LLM
采用的生成策略 - 局部最优化(标记预测)不一定能确保全局最优化(序列预测)
- 基于抽样的生成策略(如
top-p 和 top-k 等)引入的随机性
检索增强
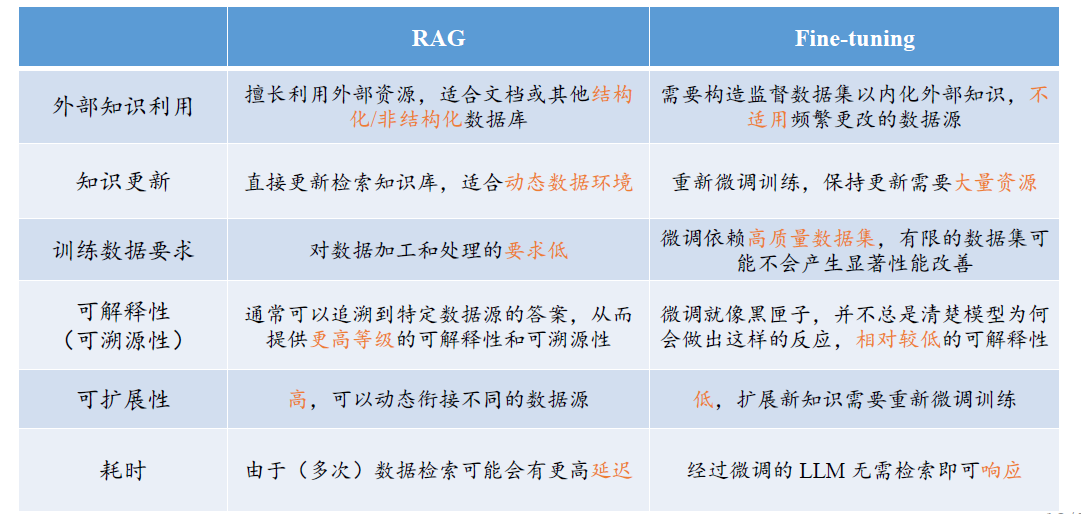
RAG
- 数据长尾分布
- 知识更新频繁
- 回答需要验证追溯
- 领域专业化知识
- 数据隐私保护
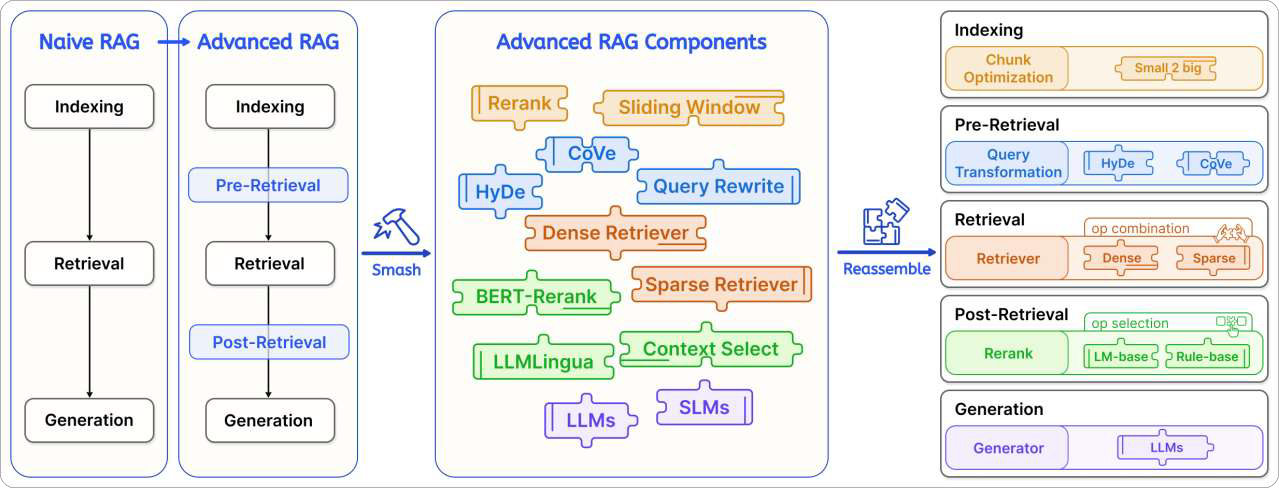
2. 主要范式
Naive RAG
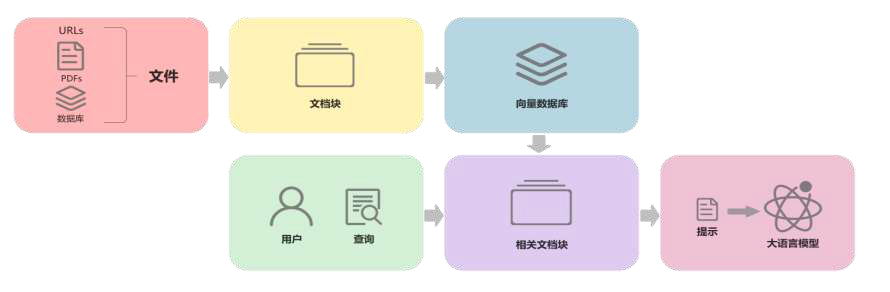
步骤
- 将文档分割成均匀的块,每个块是一段原始文本
- 利用编码模型为每个文本块生成
Embedding - 将每个块的
Embedding 存储到向量数据库中
步骤
通过向量相似度检索和问题最相关的
步骤
原始
Advanced RAG
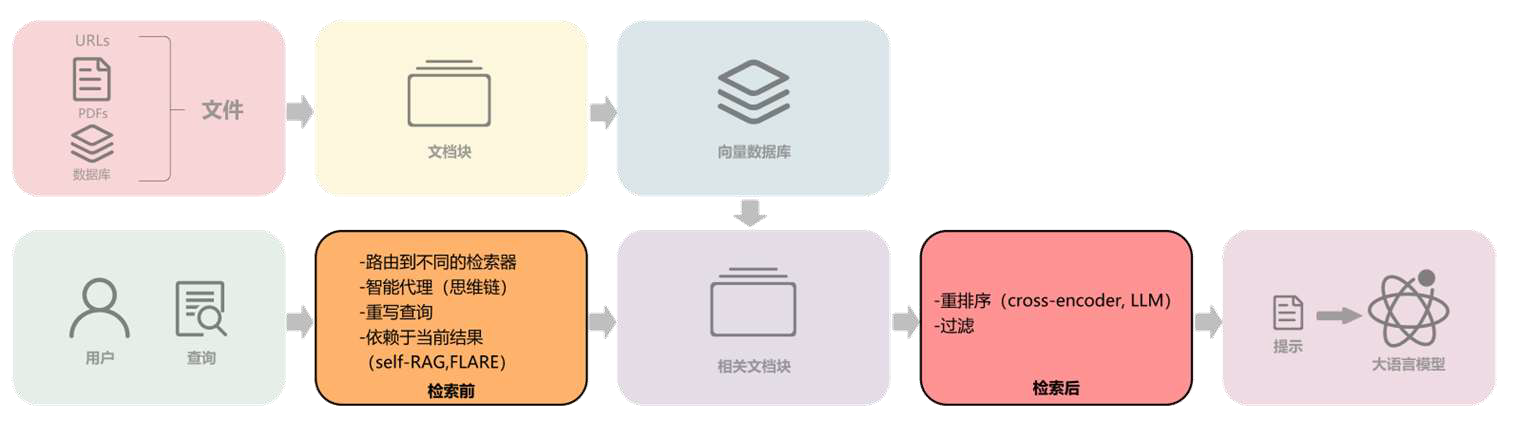
索引优化→前检索→检索→后检索→生成
- 索引优化:滑动窗口、细粒度分割、元数据
- 前检索模块:检索路由、摘要、重写、置信度判断
- 后检索模块:重排序、检索内容过滤
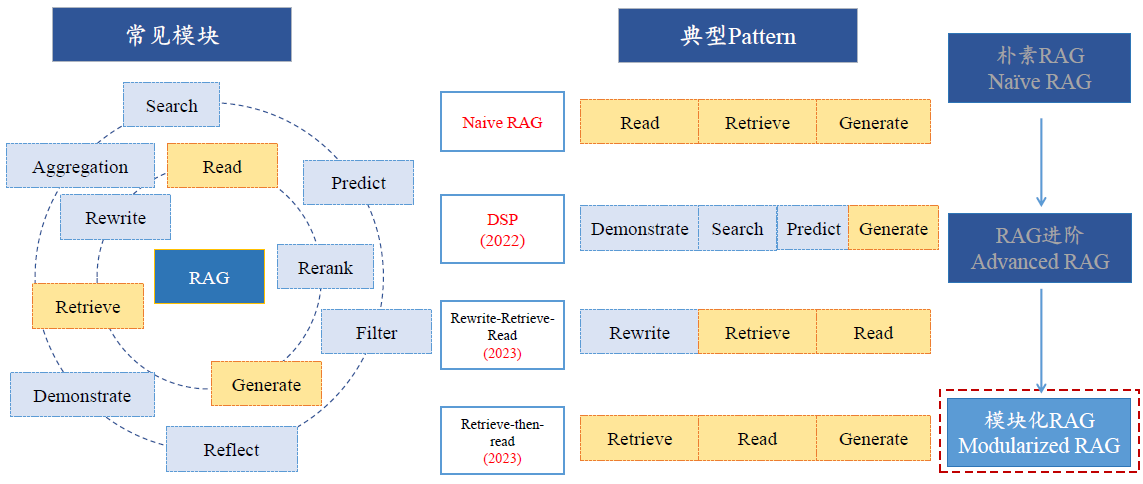
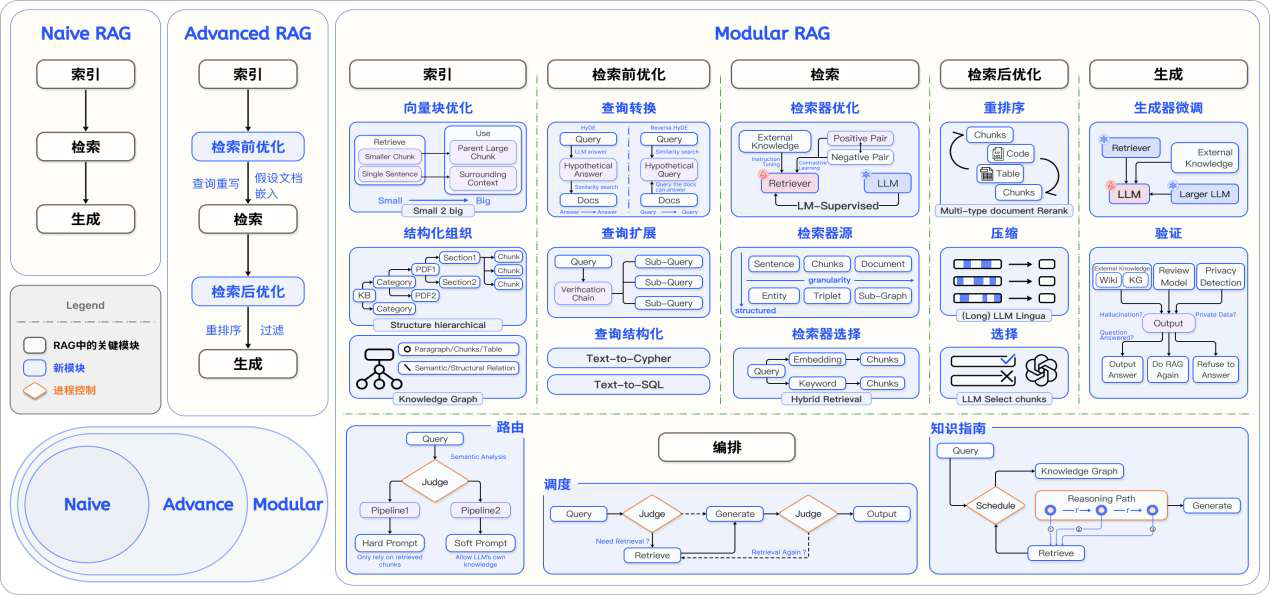
Modularized RAG
3. 关键技术

索引优化
面临的挑战:
- 文档块不完整的语义信息
- 块相似性计算不准确
- 参考轨迹不明确
数据索引优化
- 分块优化
- Small-2-Big:在句子级别嵌入文本,然后在
LLM 生成过程中扩大窗口 - 滑动窗口:滑动
Chunk 覆盖全文,避免语义割裂 - 摘要:通过摘要嵌入更大的文档。通过摘要检索文档,再从文档中检索文本块
- Small-2-Big:在句子级别嵌入文本,然后在
- 添加元数据:示例,页码,时间,类型,文档标题。
- 元数据筛选
/ 扩充 - 伪元数据生成:通过为传入的查询生成一个假设性的文档来增强检索,并生成该文本块可以回答的问题
- 元数据过滤器:对文档进行分离和标记。查询期间,除了语义查询之外,并推断元数据过滤器
结构化数据
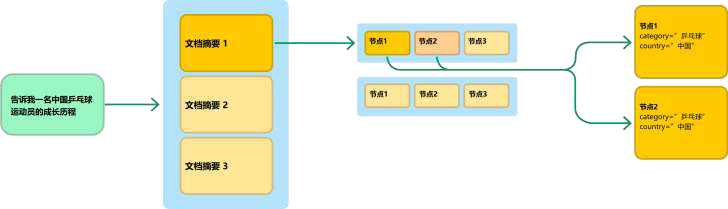
摘要→ 文档:用摘要检索代替文档检索,不仅检索直接最相关的节点,还会探索节点相关联的额外节点
文档→ 嵌入对象:文档中嵌入了对象(如表、图),先检索实体引用对象,再查询底层对象,例如文档块、数据库、子节点
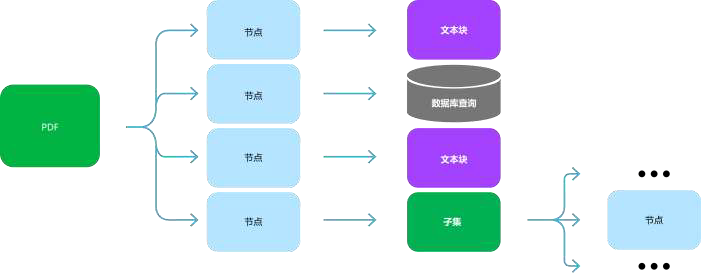
文档结构化
- 让模型回答的更准确,召回需要更细化,文档分级、做更细致的解析
- 将知识库的整个体系进行细化,给文档打标签等。用知识图谱组织
检索前处理
面临的挑战:
- 措辞不当的查询
- 语言自身的复杂性和歧义性
查询扩展
- 多查询 Multi-Query
- 提示工程通过
LLM 扩展查询 - 根据预设的模板选择相似的查询
- 为原始查询分配更高权重避免意图稀释
- 提示工程通过
- 子查询 Sub-Query
- 复杂的问题分解成一系列更简单的子问题
- 针对各个子问题分别检索增强生成
- 得到的中间结果与原问题合并
- 验证链 CoVe
- 通过
LLM 生成一组要问的验证问题 - 通过回答这些问题并检查是否一致执行
- 通过
查询转换
- 查询重写 Query Rewrite
- 原始查询并不总是检索的最佳选择
- LLM / 专用小模型重写查询
- 假设回答
HyDE - 构建假设回答代替原始查询去检索
- 或为
Chunk 生成假设问题作为查询依据
- 后退提示 Step-back Prompting
- 从原始问题抽象出高层次的概念问题
- 为
LLM 补充概念上的基本原理和知识
检索
三个关键因素:
- 检索效率
- 嵌入表示的质量
- 任务、数据和模型的一致性
检索源选择
检索器选择
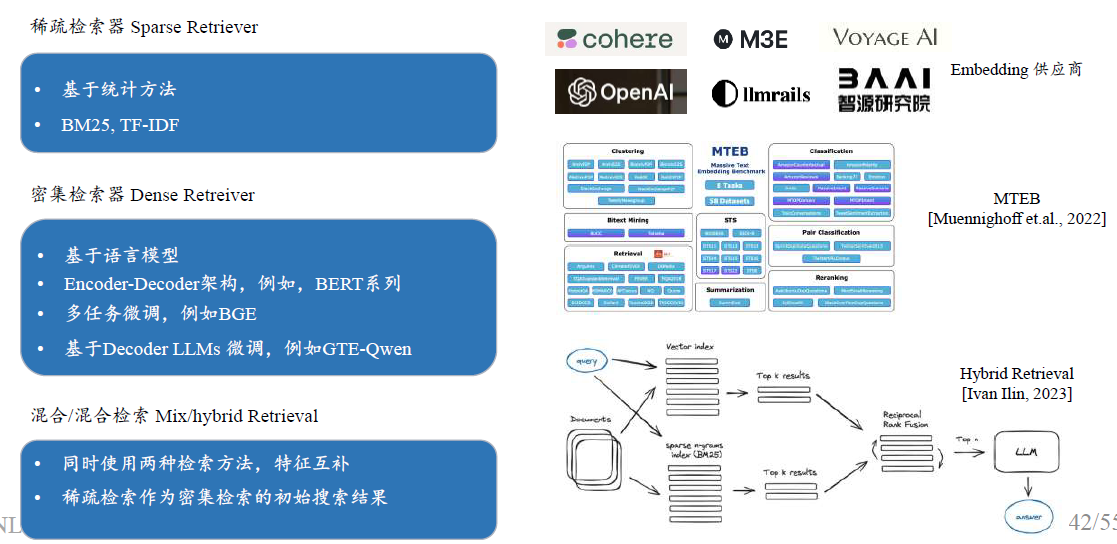
检索器微调
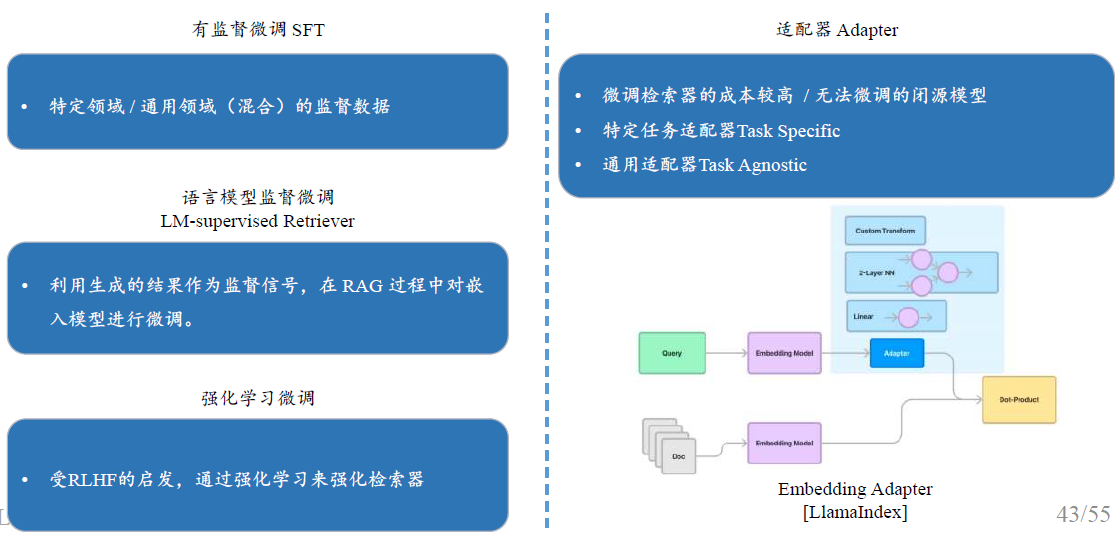
检索后处理
面临挑战:
- Lost in the middle
- 噪音
/ 反事实文档块的影响 - 上下文窗口长度限制
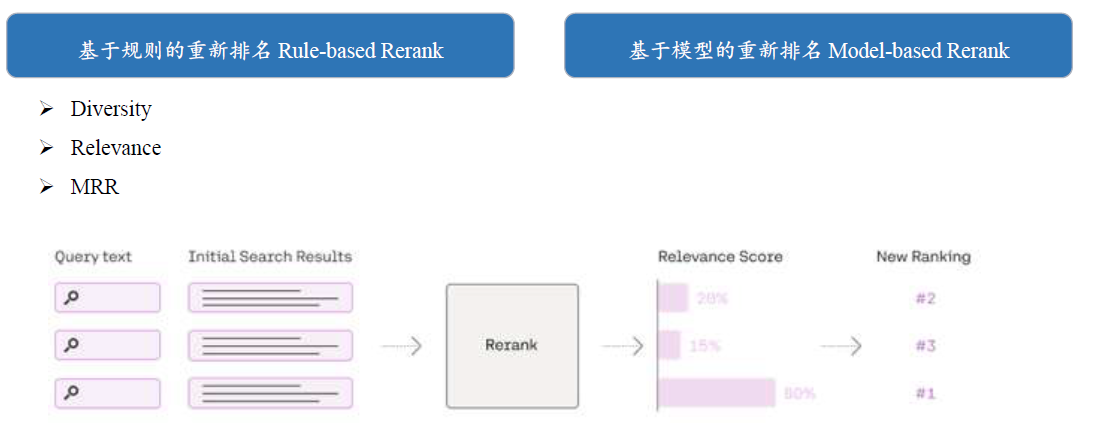
重排序
在不改变其内容或长度的情况下对检索到的文档块进行重新排序,增强更重要文档块的可见性。
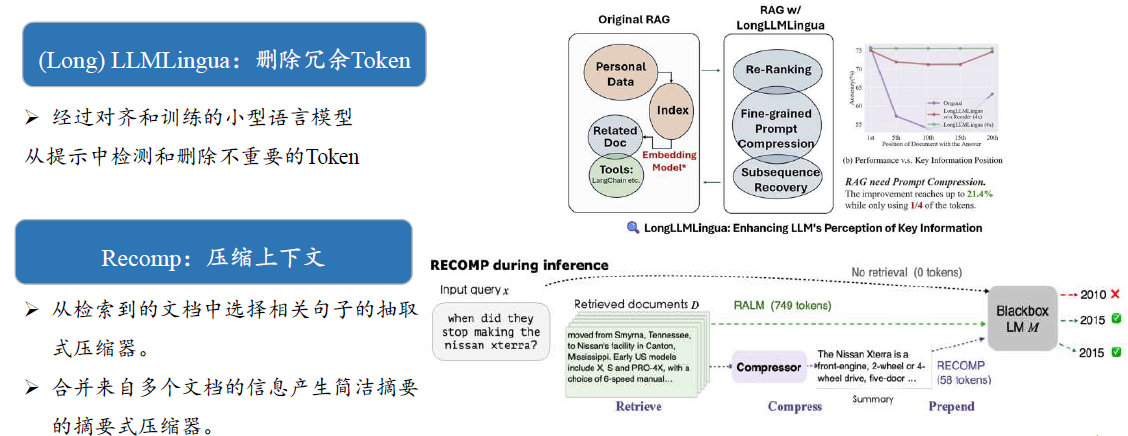
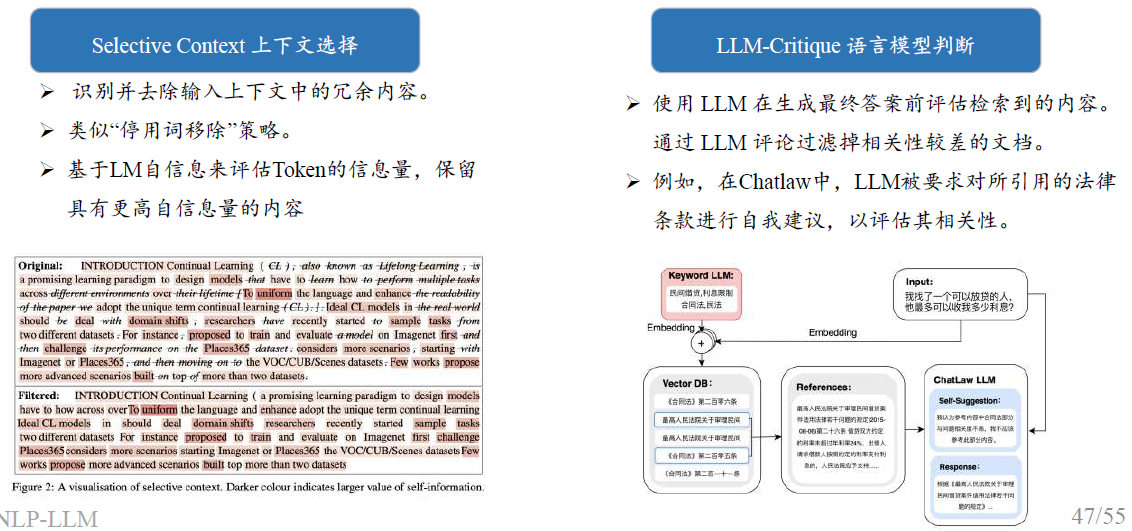
上下文压缩与筛选
RAG
生成
面临挑战:
- LLM
的选型 - 缺乏领域知识
- 复杂问题推理能力有限
- LLM
幻觉
生成器选择
事实校验
经过检索增强并不能确保无幻觉生成,尤其是检索到噪声或冲突事实时,生成后再校验减少幻觉。
编排
面临挑战:传统的链式且一次性的检索-生成流程不足以解决需要复杂推理或涉及大量知识的任务
评估

第
1. 文本分类和聚类
基于传统机器学习的文本分类
文本表示-离散表示
- 向量空间模型也称为词袋模型(BOW)
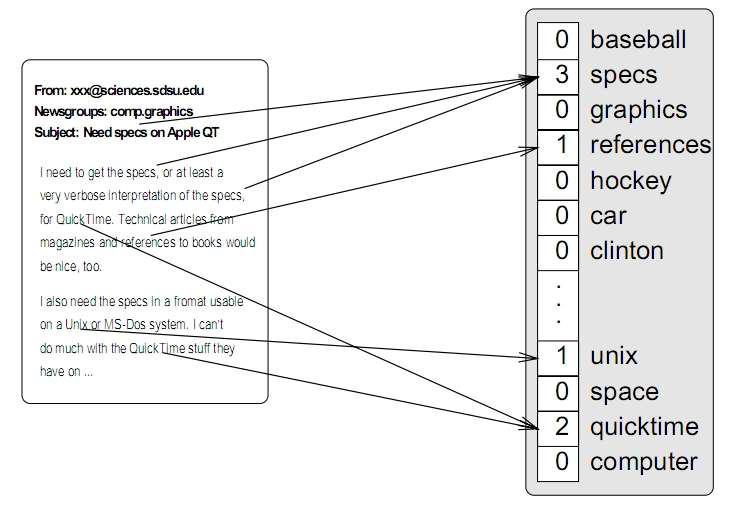
- 训练数据:带类别标签的文档
- 词袋表示:含
40 个词,即词表大小为 40
特征选择(特征过滤)
- 互信息
(Mutual Information, MI) - 信息增益
(Information Gain, IG) - Chi-Square
统计 (Chi-Square Statistics,CHI)
分类算法
- 朴素贝叶斯(Naïve Bayes)
- 支持向量机(SupportVectorMachine)
- 最大熵模型(MaximumEntropy)

NB
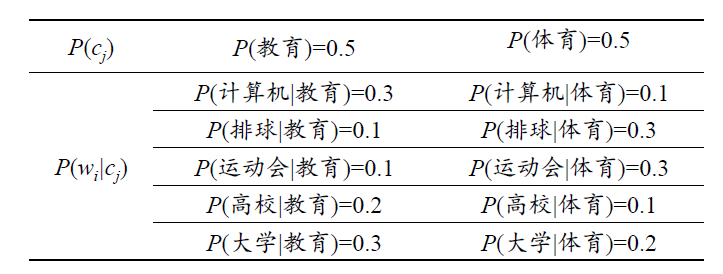

- 判别式模型
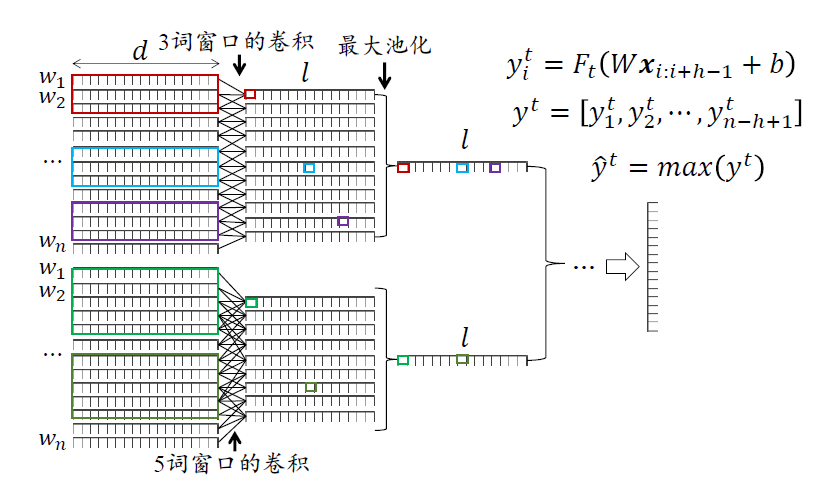
- 基于卷积神经网络的方法
- 预训练
+ 微调的方法
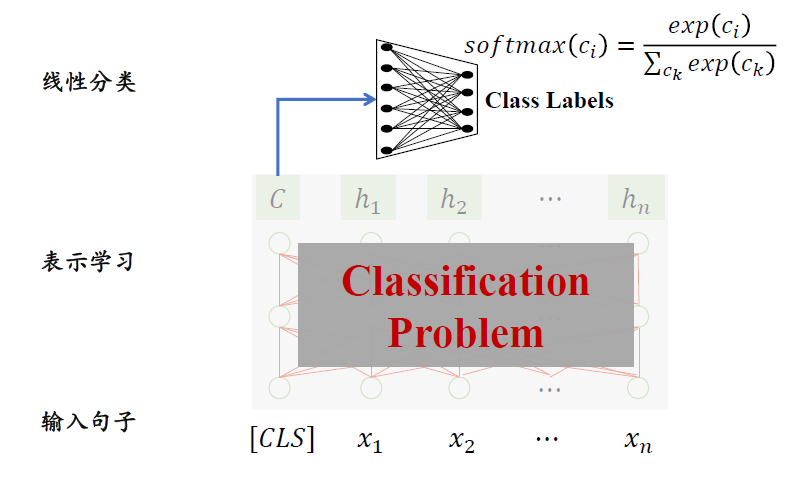
- 预训练
+ 提示的方法

- 大语言模型方法
文本分类性能评估
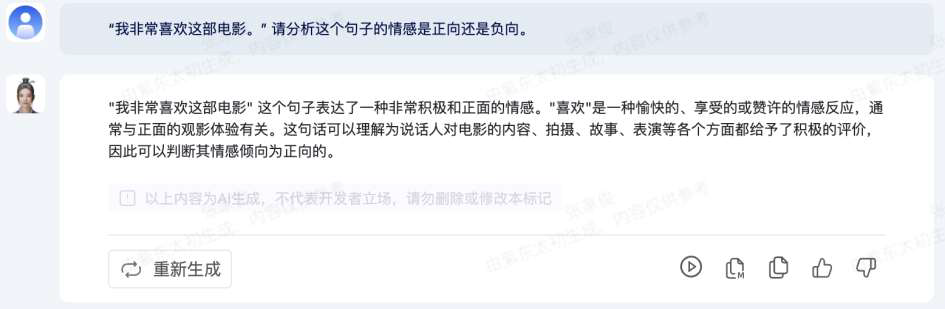
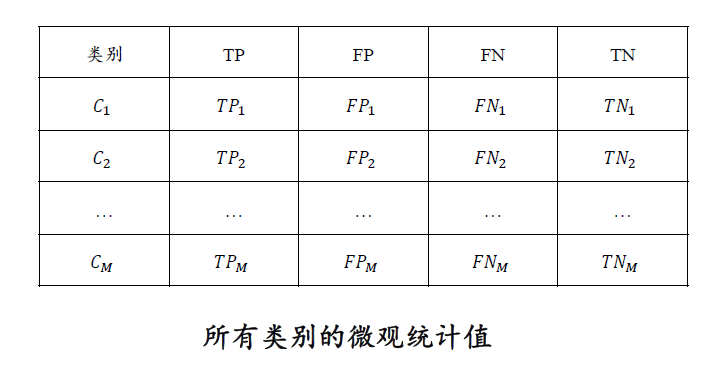
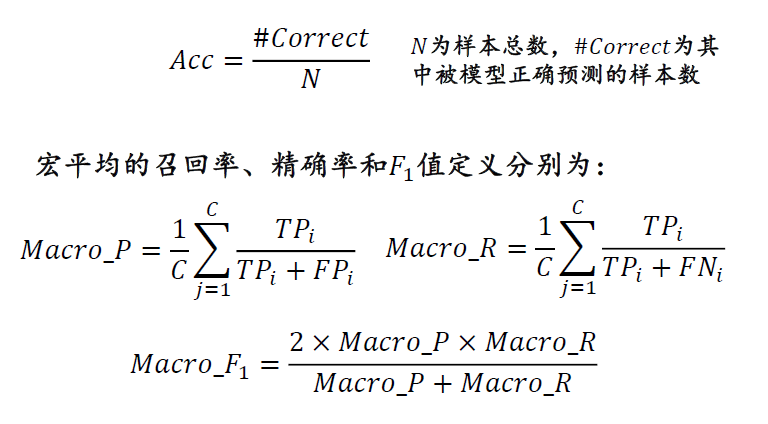
假设一个文本分类任务共有𝑀个类别,类别名称分别为𝐶1, … , 𝐶𝑀。在完成分类任务以后,对于每一类都可以统计出真正例、真负例、假正例和假负例四种情形的样本数目。
- 真正例 (True Positive, TP):模型正确预测为正例(即模型预测属于该类,真实标签属于该类)。
- 真负例 (True Negative, TN): 模型正确预测为负例(即模型预测不属该类,真实标签不属该类)。
- 假正例 (False Positive, FP):模型错误预测为正例(即模型预测属于该类,真实标签不属该类)。
- 假负例 (False Negative, FN):模型错误预测为负例(即模型预测不属该类,真实标签属于该类)。
(1)
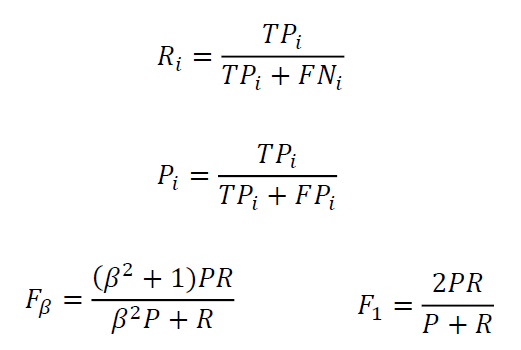
(2)

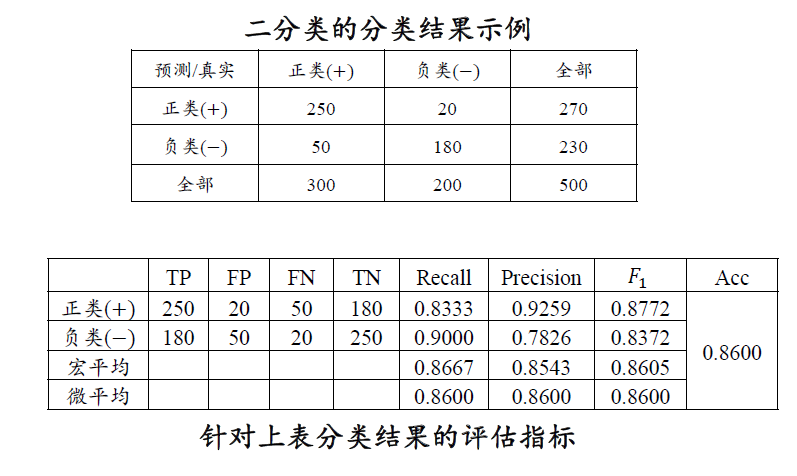
(3)P-R
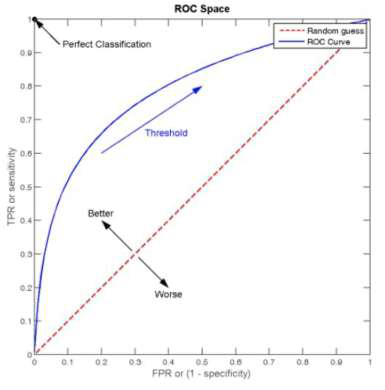
通过调整分类器的阈值,将按输出排序的样本序列分割为两部分,大于阈值的预测为正类,小于阈值的预测为负类,从而得到不同的召回率和精确率。如设置阈值为
以假正率(false positive rate)作为横坐标,以真正率(true positive
rate)(即召回率)作为纵坐标,绘制出的曲线称为
文本聚类
聚类利用无监督学习将数据划分为不同的簇
文本相似性度量
文本聚类中三种常见的文本相似性度量指标:
- 两个文本对象之间的相似度
令𝒂, 𝒃分别表示两个待比较文本的向量表示(如预训练模型向量)
(1)基于距离的度量
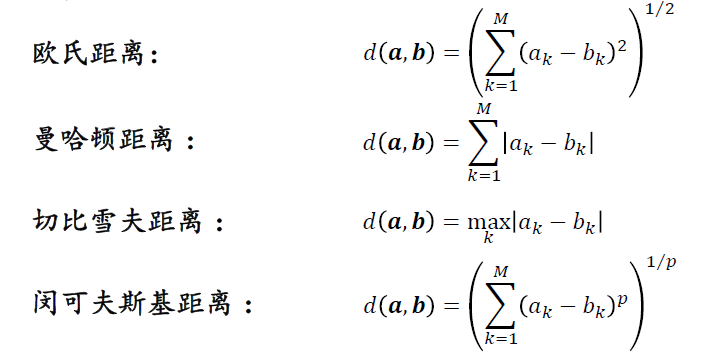
(2)基于夹角余弦的度量
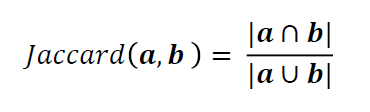
(4)基于分布的度量
令𝑷, 𝑸分别表示两个待比较文本的概率分布表示
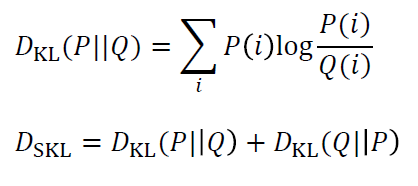
- 两个文本集合之间的相似度
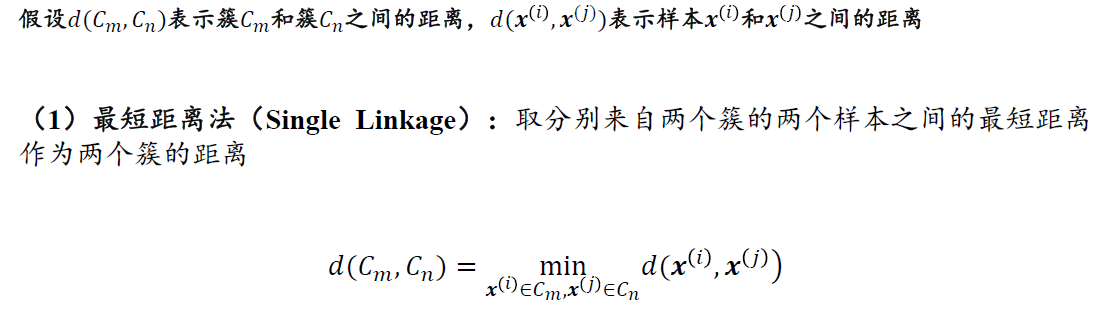


- 文本对象与文本集合的相似性
- 样本与簇之间的相似性通常转化为样本间的相似度或簇间的相似度进行计算。
- 如果用均值向量来表示一个簇,那么样本与簇之间的相似性可以转化为样本与均值向量的样本相似性。
- 如果将一个样本视为一个簇,那么就可以采用前面介绍的簇间的相似性度量方法进行计算。
文本聚类算法
- K-均值聚类
- 单遍聚类
- 层次聚类
- 密度聚类


文本聚类性能评估
- 外部标准
- 通过测量聚类结果与参考标准的一致性评价聚类结果的优劣;
- 参考标准通常由专家构建或人工标注获得。




- 内部标准
- 基于内部标准的聚类性能评价方法不依赖于外部标注,而仅靠考察聚类本身的分布结构评估聚类的性能。
- 主要思路:簇间越分离(相似度越低)越好,簇内越凝聚(相似度越高)越好。
- 常用方法:轮廓系数


2. 信息抽取
概述
定义:信息抽取是从非结构化、半结构化的自然语言文本(如网页新闻、学术文献、社交媒体等)中抽取实体、实体属性、实体间的关系以及事件等事实信息,并形成结构化数据输出的一种文本数据挖掘技术。、
简而言之,是从非结构化文本到机器可读信息的一种转换技术。
主要任务:实体识别、实体消歧、关系抽取、事件抽取。
实体识别
定义
- 命名实体识别是信息抽取的一项基础任务
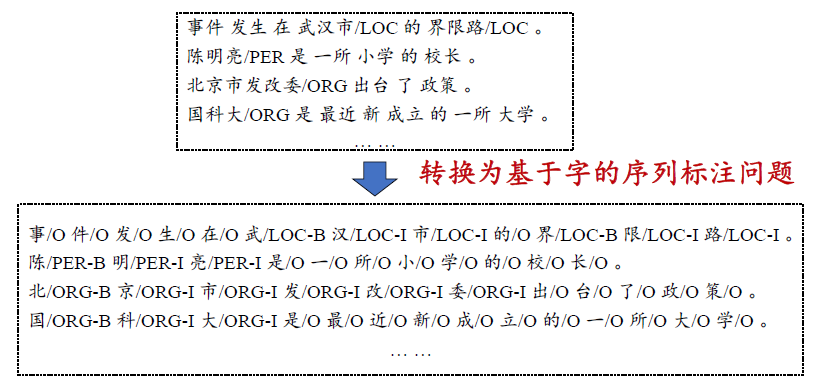
- 自动识别出文本中指定类别的实体,包括人名、地名、机构名、日期、时间、货币和百分比等七类
- 人名(例如
“乔布斯”)、地名(例如 “北京”)、组织机构名(例如 “中国科学院”)、时间(例如 “10 点 30 分”)、日期(例如 “2017 年 6 月 1 日”)、货币(例如 “1000 美元”)、百分比(例如 “百分之五十”) - 由于时间、日期、货币和百分比规则性强,利用模板或正则表达式基本可处理,人名、地名和组织机构名是关注重点
包含两个任务:实体检测和实体分类:
- 实体检测:检测出文本中哪些词串属于实体,也即发现实体的左边界和右边界
- 实体分类:判别检测出的实体具体属于哪个类别
典型方法——基于有监督的机器学习方法
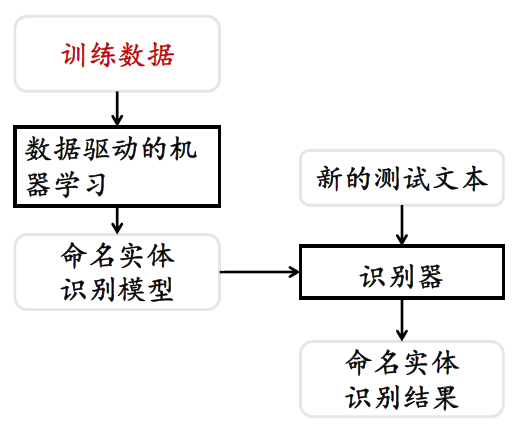
- 训练数据规范化
- 基于隐马尔科夫模型的命名实体识别

- 基于预训练模型
BERT 的命名实体识别

- 基于大语言模型的命名实体识别
自动评价


关系抽取
定义
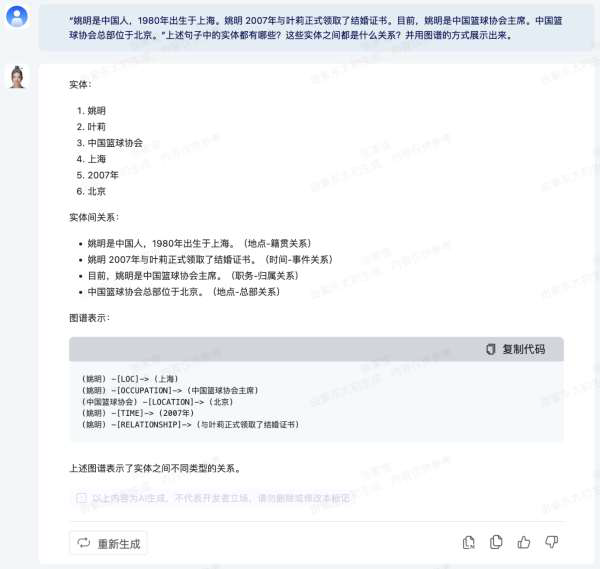
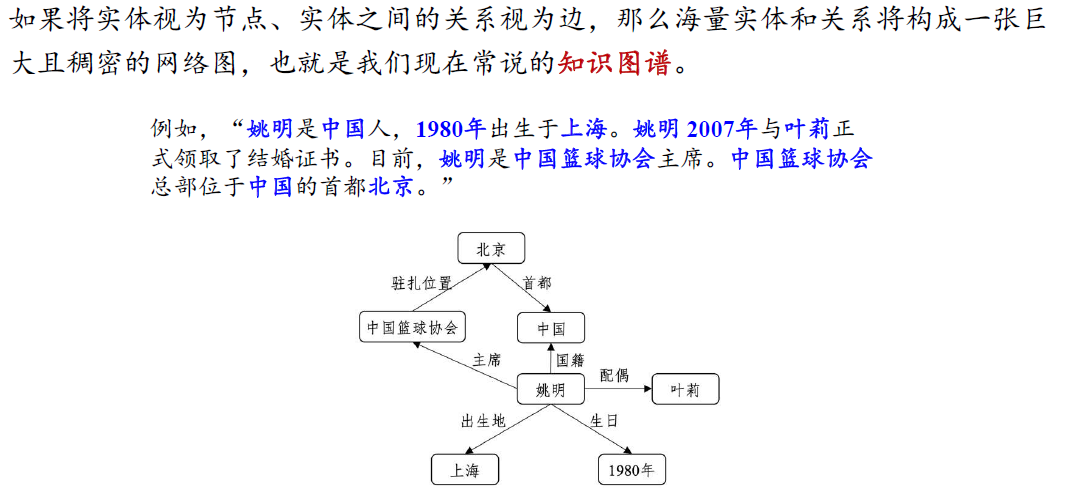
- 识别文本中的实体并判别实体间关系的技术称为关系抽取,该技术在知识图谱构建和自动问答等任务中扮演着关键角色
- 例子:姚明是上海人。姚明
2007 年与叶莉正式领取了结婚证书。 - 实体识别:[姚明]
是 [上海] 人。[姚明]2007 年与 [叶莉] 正式领取了结婚证书。 - 关系抽取:citizen_of(姚明,上海)、spouse(姚明,叶莉)

典型方法
- 关系抽取形式化
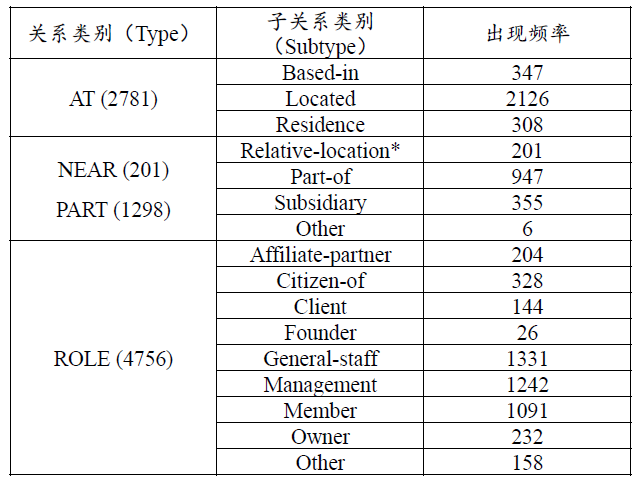
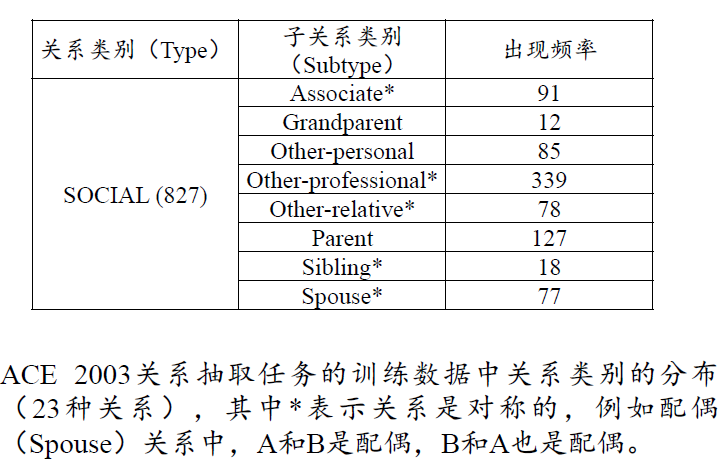
假设句子中的实体已经给定,目标在于识别实体之间的关系。关系的类别在开放域环境中有成千上万种并且未知关系类别繁多,我们将探讨限定领域给定关系类别集合下的关系识别任务。

- 基于分布式表示的关系分类
关系分类方法的关键在于如何根据实体所在的上下文准确判别一对实体之间的关系。分布式方法的核心思想体现在三个方面:1,所有特征采用分布式表示,以克服数据稀疏与语义鸿沟问题;2,采用局部表示捕捉实体对周围的上下文词汇化特征;3,采用卷积神经网络捕捉实体对所在句子的全局信息。

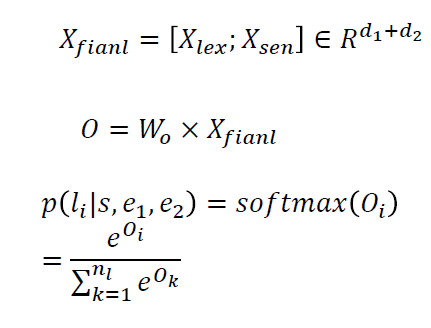
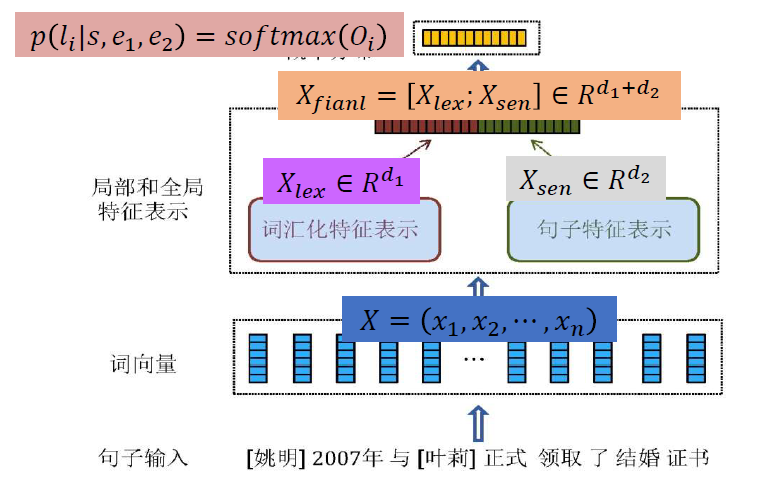
- 基于大语言模型的关系抽取
自动评价

知识图谱

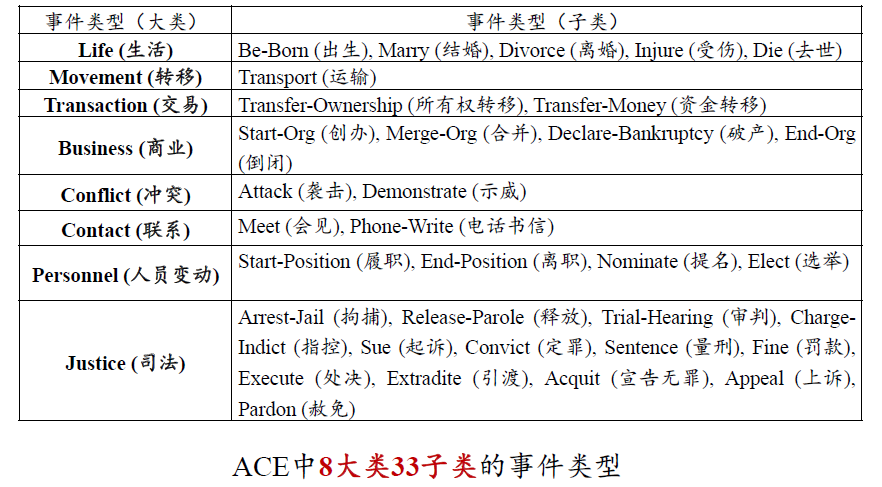
事件抽取
定义
- 事件抽取就是针对特定领域的事件进行事件元素的抽取
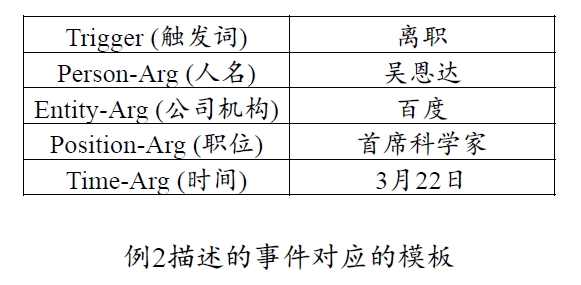
- 一个事件包括事件类型、参与者、时间、地点、原因以及诸多其他元素,不同类型的事件对应不同的组织结构
- 例如,公司收购事件包含
“收购者”、“被收购者” 和 “金额” 等,而离职事件包含 “离职者”、“公司机构”、“职位” 以及 “离职时间” 等等

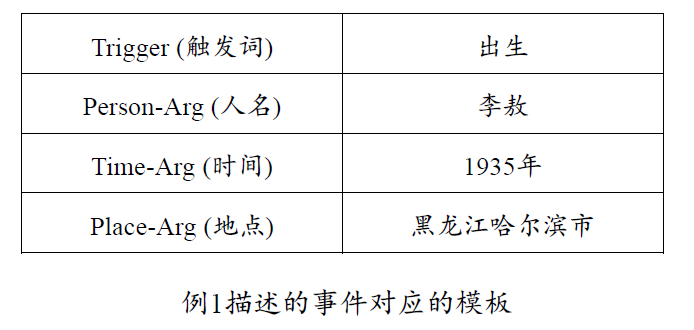
例
事件通常由一句话描述,其中一定存在一个词语,比如例
触发词是决定事件类型的核心要素,已知事件类型的前提下,抽取事件的各个元素并判别事件元素的角色是主要任务。事件角色由两大类组成:事件参与者和事件属性。
事件参与者通常是命名实体中的人名和机构名。
事件属性包括两类:通用事件属性和事件相关属性。
- 通用事件属性:事件发生的地点、时间和时长等。
- 事件相关属性:由具体的事件类型决定,例如
“定罪” 事件中的 “罪名” 属性,“履职” 事件中的 “职位” 属性,都是事件相关属性。
典型方法
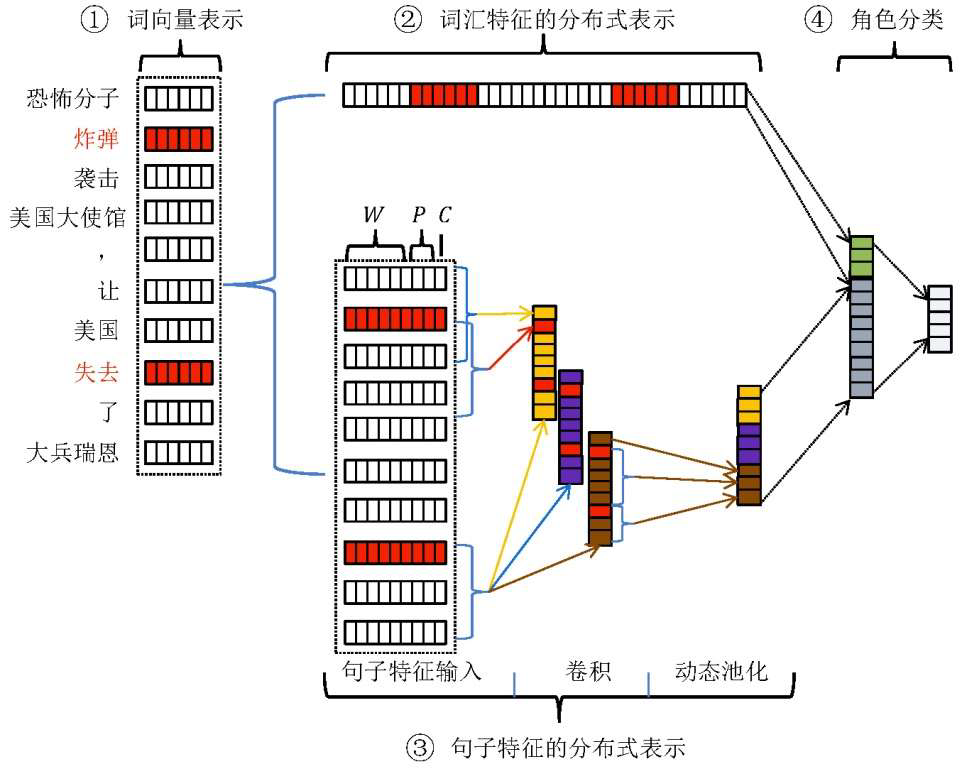
- 基于分布式模型的事件抽取
- 基于大语言模型的事件抽取

自动评价


事件图谱
事件抽取可以从文本中抽取出不同的事件,而事件和事件之间往往不是独立发生,通常蕴含着发生模式和演化规律,也即事理逻辑。
一个由事理逻辑组成的知识库称为事件图谱,描述了各事件之间的演化规律和发生模式。
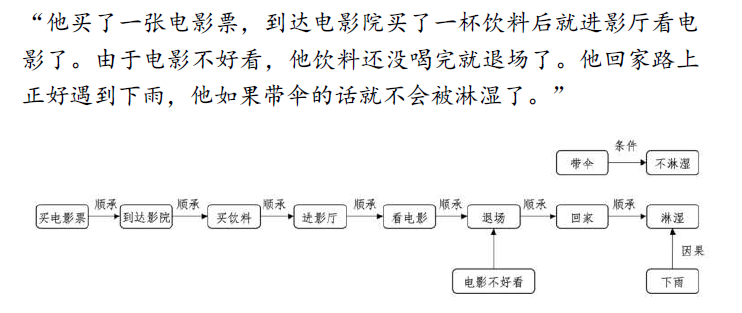
与知识图谱相比,事件图谱的节点不再是实体而是事件,每一条边表示事件之间的关系而不是实体关系。
相比于知识图谱中关系类别繁多,事件图谱中的事件关系很少,主要包括顺承、因果、条件和上下位等逻辑关系。
类似于知识图谱,事件图谱也是一种基础性知识资源,在事件预测、消费意图挖掘和推荐、问答对话、辅助决策和推理等领域都将发挥非常重要的作用,并且可以有力提升人工资能模型和系统的可解释性能力。
当前,事件图谱的还处于初步发展阶段,主要集中于金融等领域的事件图谱构建和应用,未来将会在各个应用中扮演越来越重要的作用。
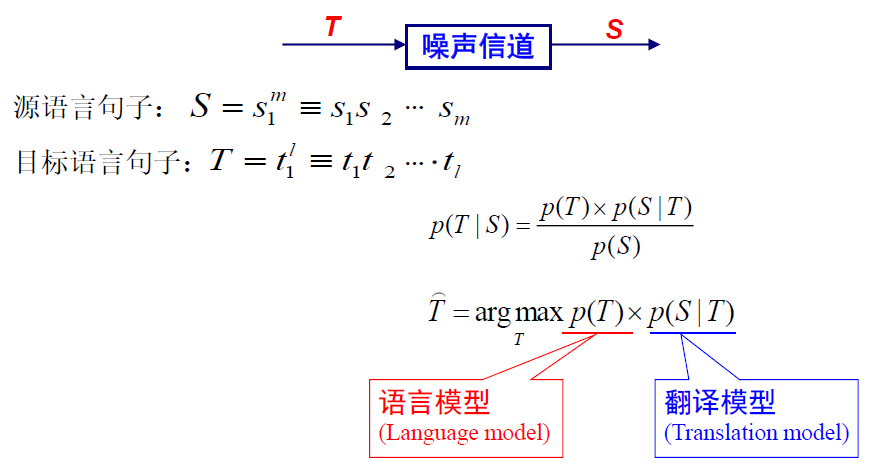
3. 机器翻译
概念:机器翻译
统计机器翻译
统计翻译的思想:
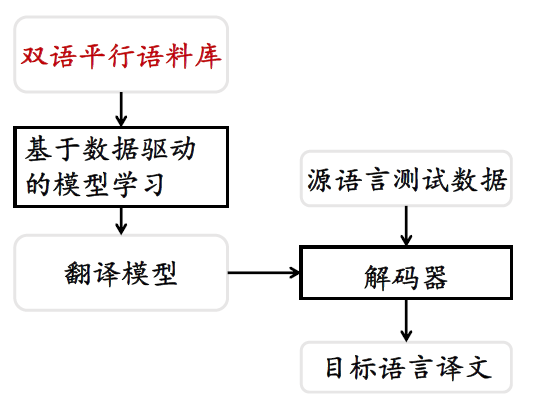
优点:1. 可解释性高;2. 模块随便加;3. 错误易追踪
缺点:1. 数据稀疏;2. 复杂结构无能为力;3. 强烈依赖先验知识
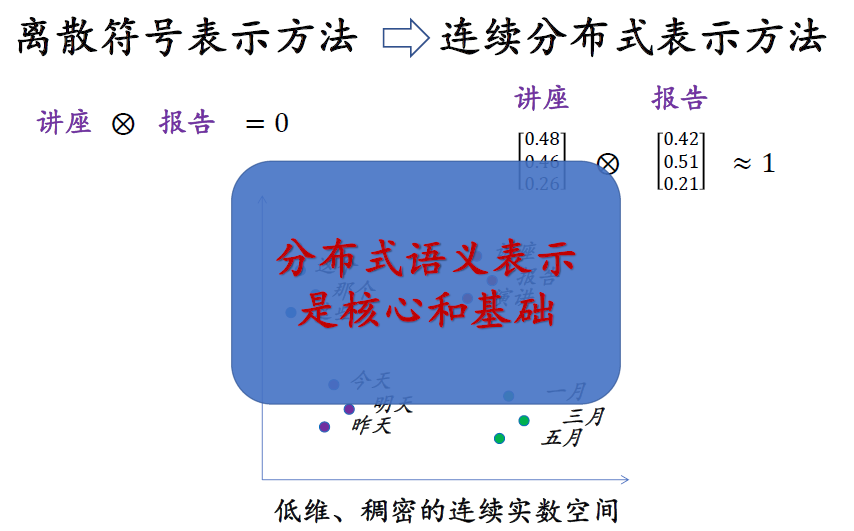
神经机器翻译
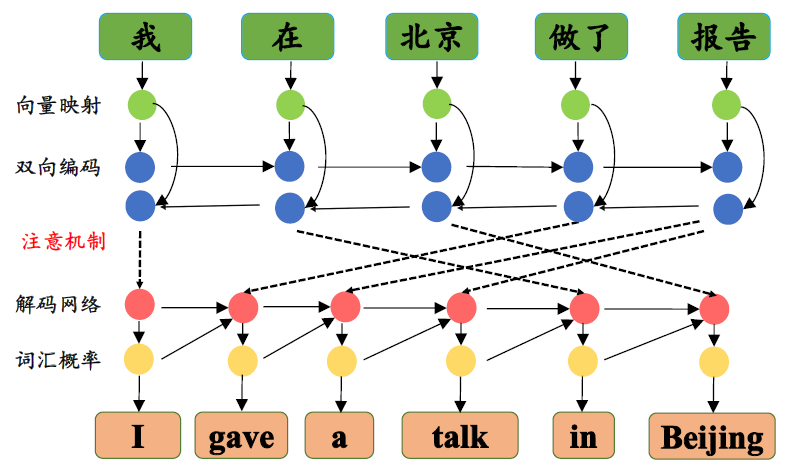
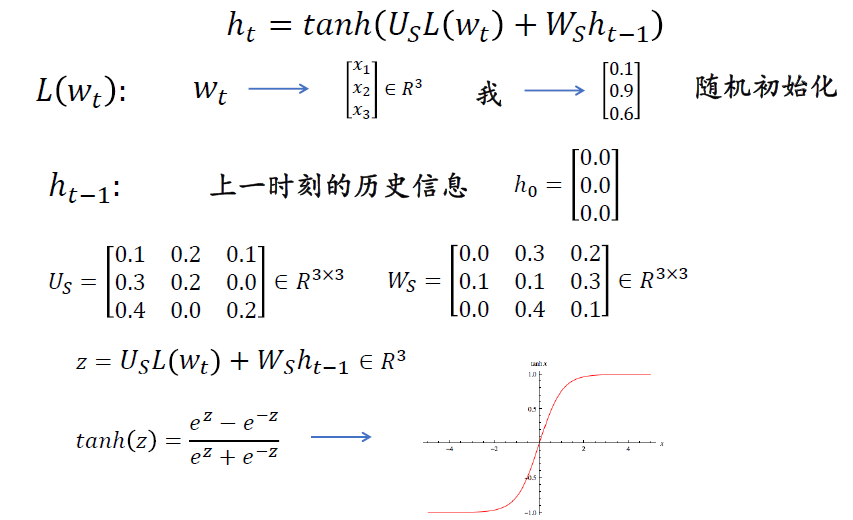
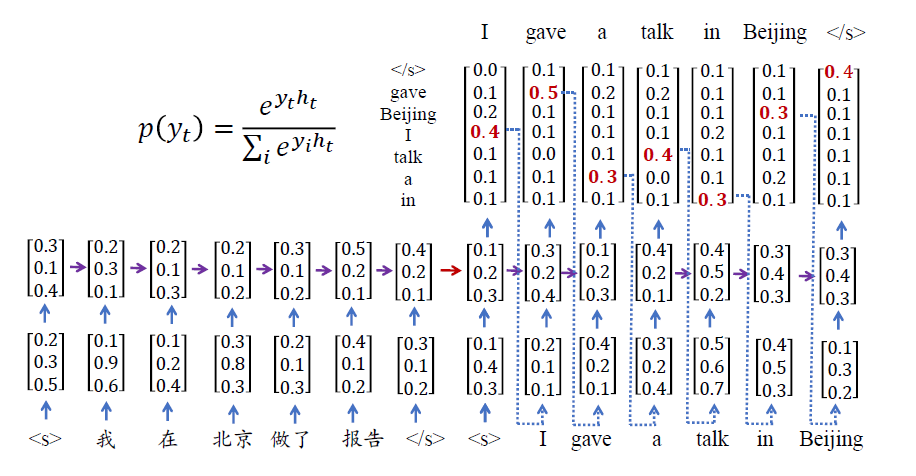
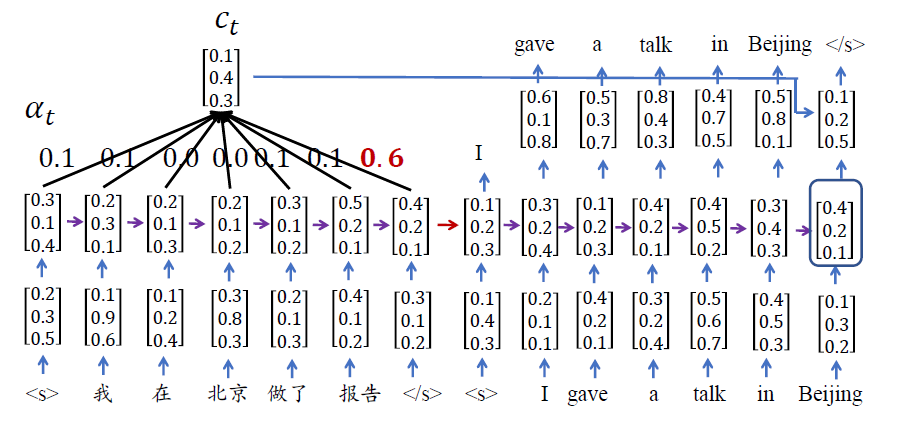
源语言编码
将源语言句子编码成一个实数向量语义表示
目标语言解码
将源语言句子的语义表示解码生成目标语言句子
注意机制
译文评估方法
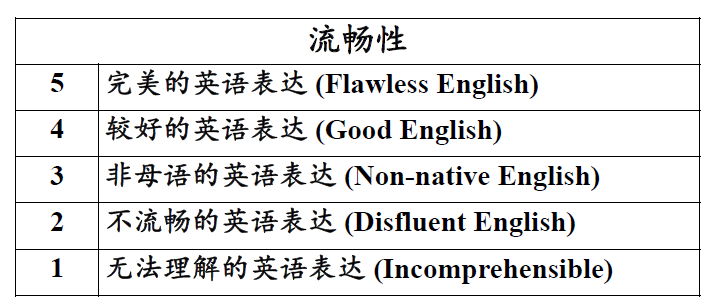
主观评测
考察因素: (1)


客观评测
- 句子错误率:译文与参考答案不完全相同的句子为错误句子。错误句子占全部译文的比率。
- 单词错误率
(Multiple Word Error Rate on Multiple Reference, 记作 mWER):分别计算译文与每个参考译文的编辑距离,以最短的为评分依据,进行归一化处理。
- 编辑距离:以插入、删除和替换为基本操作,将一个序列转换为另一个序列所需的最少操作次数。
(3)
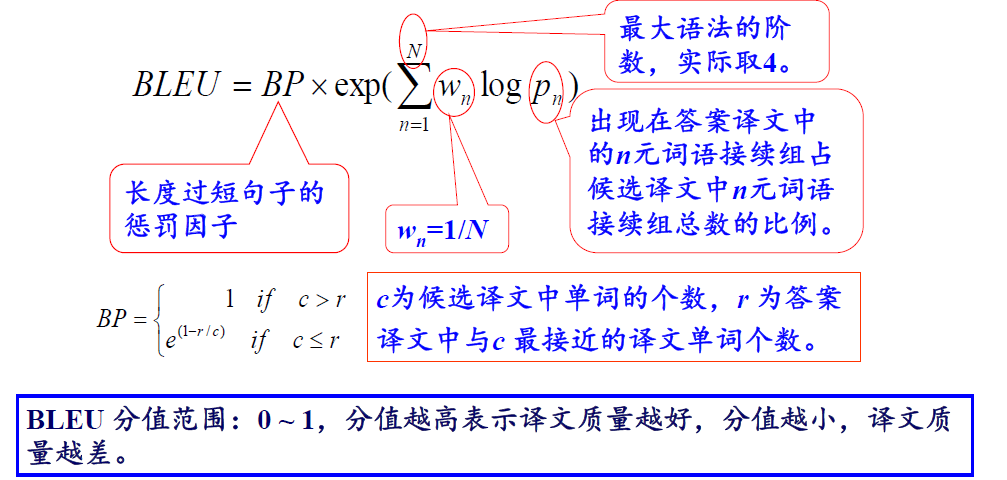
- BLEU
评价方法 [Papineni, 2002]-BiLingual Evaluation Understudy, IBM
- 基本思想:将机器翻译产生的候选译文与人翻译的多个参考译文相比较,越接近,候选译文的正确率越高。
- 实现方法:统计同时出现在系统译文和参考译文中的
n 元词的个数,最后把匹配到的 n 元词的数目除以系统译文的 n 元词数目,得到评测结果。