人工智能相关问题总结
正则化项只是在损失函数后面加了一项,为什么可以降低
0. VC
VC
VC
要理解
想象有一组数据点,我们要用一个模型(比如一条直线)把它们分成两类(正类和负类,即二分类问题)。
- 如果有 N 个点,这 N 个点理论上共有 2N 种可能的标签组合(比如全正、全负、一正一负等)。
- 如果对于这 N
个点的任何一种标签组合,模型都能找到一种参数设定,把它们完美地分开(训练误差为
0),我们就说这个模型能打散这 N 个点。
所以,VC
- 记作: VC(H)
- 含义:
- 如果存在至少一组 N
个点能被模型打散,且不存在任何一组 N + 1
个点能被模型打散,那么该模型的
VC 维就是 N。 - 注意: 只要找到
“任意一组” N 个点能被打散即可,不需要所有的 N 个点组合都能被打散。但在 N + 1 时,必须是 “所有” 组合都无法被打散。
- 如果存在至少一组 N
个点能被模型打散,且不存在任何一组 N + 1
个点能被模型打散,那么该模型的
1.
几何直觉:从
想象你在训练一个线性回归模型 y = w1x1 + w2x2。
- 没有正则化时: 参数 w1, w2 可以是任意实数。你的搜索空间是整个二维平面。在这个巨大的空间里,模型可以拟合幅度极大的变化,这对应着很高的复杂度(高 h)。
- 加上 L2 正则化 (w12 + w22 ≤ C):
虽然你是在 loss 后面加了 λ||w||2,但这在数学上等价于告诉模型:“你只能在半径为
的圆圈内找参数”。 - 结果:
你的搜索空间从
“无限大的平面” 缩小到了 “一个小圆圈”。 - 结论:
一个只能在圆圈里取值的模型,显然比一个可以在全宇宙取值的模型
“弱”。这种人为变弱,就是降低 VC 维的过程。
- 结果:
你的搜索空间从
2. 数学解释:权重衰减 (Weight Decay) 与平滑度
VC 维的一个核心来源是模型对数据微小变化的敏感度。
- 高 VC 维的表现: 模型参数 w 很大。当输入 x 稍微变化一点点,输出 y = w ⋅ x
就会剧烈波动。这种
“剧烈波动” 的能力让模型可以强行穿过每一个噪声点(过拟合)。 - 正则化的作用: 正则化项(如 λ||w||2)强迫参数
w 保持很小。
- 当 w 很小时,函数变得非常平滑。
- 平滑的函数无法像心电图一样上下乱窜去拟合噪声。
- 丧失了
“乱窜” 的能力 = 丧失了拟合任意复杂数据的能力 = 降低了 VC 维。
3. 本质:软约束 vs 硬约束
“VC 维定义不是看参数个数吗?加了正则化,参数个数没变啊?”
- 理论 VC 维 (Theoretical VC dim): 确实通常由参数数量决定(比如 d + 1)。
- 有效 VC 维 (Effective VC dim): 实际上模型能表现出的复杂度。
正则化并没有改变参数的个数,但它极大地限制了参数的取值范围(也就是参数的
正则化项虽然是
L1 和 L2 正则化在几何图像上有什么区别?
要理解为什么 L1 (Lasso) 能把参数变成 0(稀疏解),而 L2 (Ridge) 只能把参数变小,我们必须通过几何图像来看。
想象我们在一个二维平面上,只有两个参数 w1 和 w2。
1. 两股力量的对抗
我们的目标是最小化总损失:Losstotal = Lossdata + λ ⋅ Regularization。这在数学上等价于:在限制正则化项不超过某个值 C 的情况下,尽可能最小化数据误差。
这就变成了两股力量的
- 数据误差(Loss):它的等高线通常是一圈圈的椭圆。椭圆的中心是误差最小的完美点,越往外误差越大。模型拼命想往圆心钻。
- 正则化项(Constraint):它是围绕原点 (0, 0) 的一个限制区域。模型参数 w 被锁在这个区域里,不能跑出去。
最优解(最佳参数)就在
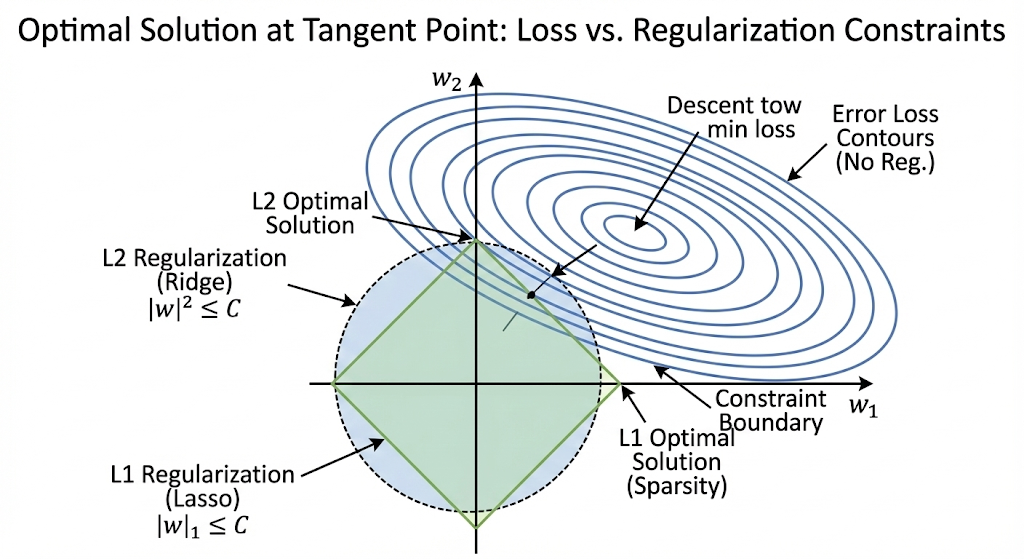
2. L2 正则化:圆形的
- 正则项形状: w12 + w22 ≤ C。这是一个圆(在高维是球体)。
- 接触过程:
- 误差椭圆慢慢扩大,去触碰原点周围的这个圆。
- 关键点: 圆是非常光滑的,它没有
“棱角”。 - 椭圆和圆的切点,通常会落在圆周的任意位置。
- 结果: 切点的坐标 (w1, w2) 通常两个都不是 0(比如 w1 = 0.2, w2 = −0.5)。
- 结论: L2 只是限制参数不要离原点太远(变小),但很难让它们恰好落在坐标轴上(变 0)。
3. L1 正则化:菱形的
- 正则项形状: |w1|+|w2| ≤ C。这是一个菱形(或者说是旋转了 45 度的正方形)。
- 接触过程:
- 这个菱形有 4 个非常突出的尖角(Corners),这些尖角刚好就在坐标轴上(比如 (C, 0) 或 (0, C))。
- 当误差椭圆扩大去触碰这个菱形时,由于尖角向外突出,椭圆极大概率会先碰到尖角,而不是碰到平滑的边。
- 结果: 一旦切点落在尖角上,你可以看看坐标——在这个例子中,切点是 (w1, 0) 或者 (0, w2)。
- 结论: 这就产生了 0!
某个参数变成了
0,意味着对应的特征被
“删掉” 了。这就是稀疏性(Sparsity)的来源。
| 特性 | L2 正则化 (Ridge) | L1 正则化 (Lasso) |
|---|---|---|
| 几何形状 | 圆 / 球体 (平滑) | 菱形 / 多面体 (有尖角) |
| 触碰点 | 通常在圆弧边缘 | 极大概率在尖角(顶点) |
| 参数变化 | 整体变小,接近 0 | 很多参数直接变为 0 |
| 主要功能 | 防止过拟合,处理共线性 | 特征选择 (自动去掉无用特征) |
| 数学性质 | 处处可导 | 在 0 点处不可导 (所以产生了稀疏解) |