多智能体系统知识总结
多智能体系统介绍
智能体与多智能体系统基础
智能体是一种能够在特定环境中自主行动以实现其设计目标的计算机系统。
- 能够代表其用户或所有者独立行动,并展现出对其内部状态的控制能力。
- 能够自行领会满足设计目标所需的工作,而非持续依赖指令。
多智能体系统由若干智能体构成,这些智能体彼此交互。
- 在最普遍的情况下,智能体将代表具有不同目标和动机的用户进行行动。
- 为了成功交互,它们需要具备相互协作、配合与协调的能力,正如人类之间的互动方式。
智能体的特性
- 情境化
(Situated):在动态 / 不确定环境中感知与行动 - 灵活性
(Flexible):反应式(响应环境变化),主动式(目标导向行为) - 自主性
(Autonomous):对其自身行动行使控制权 - 持续性
(Persistent):持续运行的进程 - 社会性
(Social) :与其他智能体 / 人进行交互
BDI
在智能体研究领域,BDI
- 识别实践推理中意图的特性
- 意图具有前瞻性,可引导智能体规划并约束其采纳其他意图
- 意图作为智能体行动计划的构成要素,用以组织当前及未来的行为
实践推理中的意图
■ 意图为智能体带来需要解决的问题,智能体必须找到实现这些意图的方法 - 若我怀有实现
■ 意图构成采纳其他意图的
“筛选机制”,新意图不得与既有意图冲突 - 若我已持有实现 相冲突的意图 ■ 智能体追踪其意图的实现状态,若尝试失败则倾向于再次尝试 - 若智能体首次实现
Bratman
- 智能体的信念代表其对世界认知的信息
- 智能体的愿望代表其期望实现的事态
- 智能体的意图代表其已作出行动承诺的愿望
智能体之所以进行规划,是因为其资源具有有限性
- 智能体必须制定并坚持执行计划(即确定计划)
- “坚持”
意味着持续遵循计划,不轻易放弃
- “坚持”
- 承诺对推理形成约束:
- 为智能体界定问题范围(明确需要推理的内容):智能体需确定如何履行承诺
- 提供可行性筛选机制(明确无需推理的内容):智能体将排除与承诺相冲突的选项
- 意图是一种已承诺的计划(例如我的下一次旅程)
规划问题求解
规划本质上是为了达成某些预期目标而自动生成一系列行动方案的过程。
规划算法的特性:
可靠性
若规划算法所有解均为合法计划,则该算法是可靠的
所有前提条件、目标及额外约束均须得到满足
完备性
- 若实际存在解时规划算法总能找到解,则该算法是完备的
- 若搜索空间包含所有解,则该规划算法是严格完备的
最优性
- 若规划算法能最大化预设的规划质量度量标准,则该算法具有最优性。
类
极具影响力的动作表示法:
- 前提条件:需为真的命题列表
- 删除表:将变为假的命题列表
- 增加表:将变为真的命题列表
Example:

框架问题
如何高效地表示所有未发生改变的部分?
我从家前往商店,由此创造了一个新的情境
- 商店仍在售卖薯片
- 我的年龄保持不变
- 北京依然是中国的首都……
分支问题
我们是否要在动作定义中说明所有这些内容?
我从家前往商店,由此创造了新情境
- 我此刻位于中关村
- 店内人数增加了
1
- 我口袋中的物品现已转移至店内
STRIPS Treatment
在
- 原始事实(例如
at(home))会在状态间持续存在,除非发生改变。 - 推断事实不会被保留,必须重新推断。
- 这可以避免出错,但可能效率较低。
手段目的分析
STRIPS
- 通过缩减当前状态与目标状态之间的差异进行搜索
- 分析可用操作手段以实现预期目标
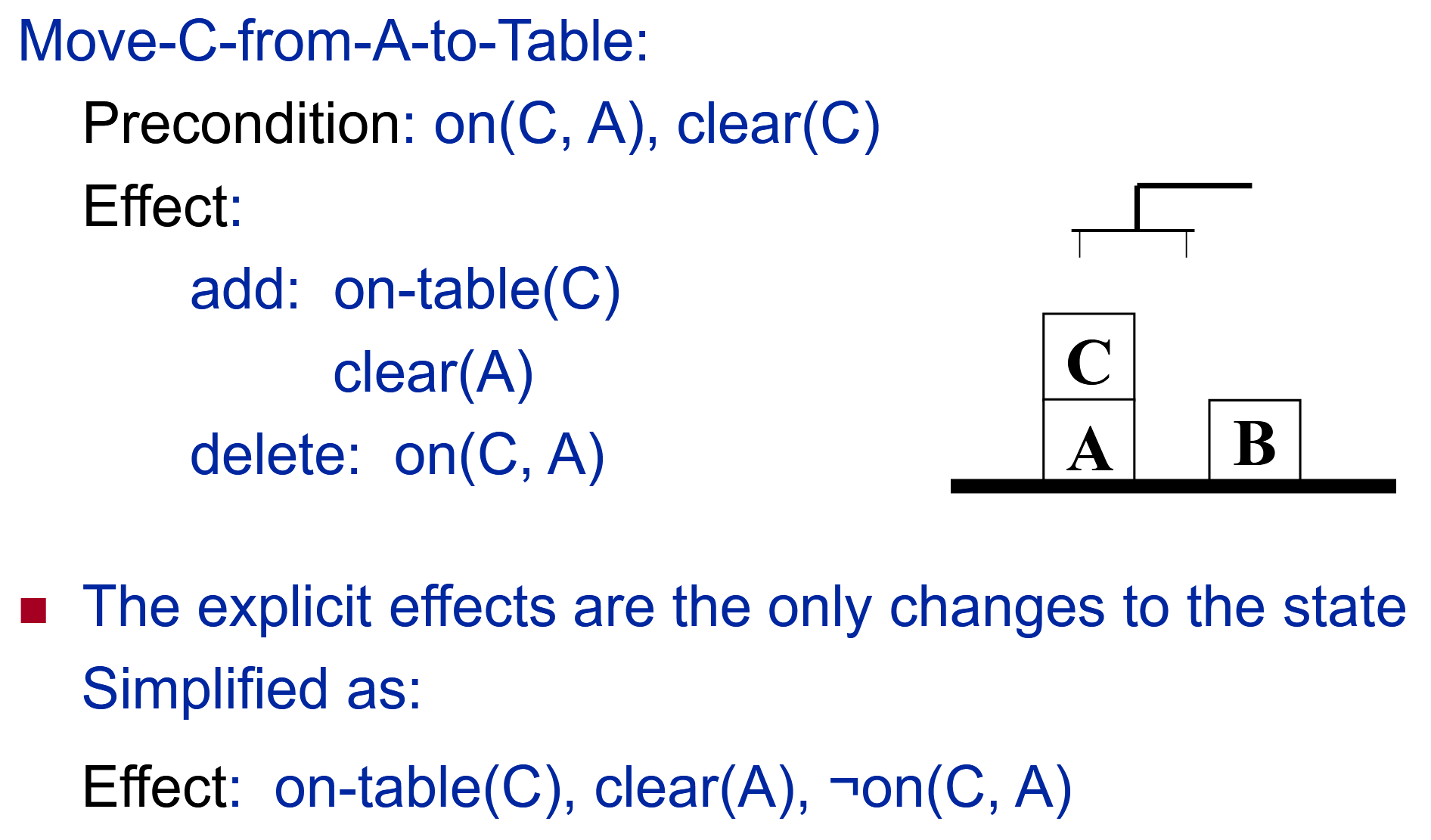
积木世界示例(苏斯曼异常)
STRIPS
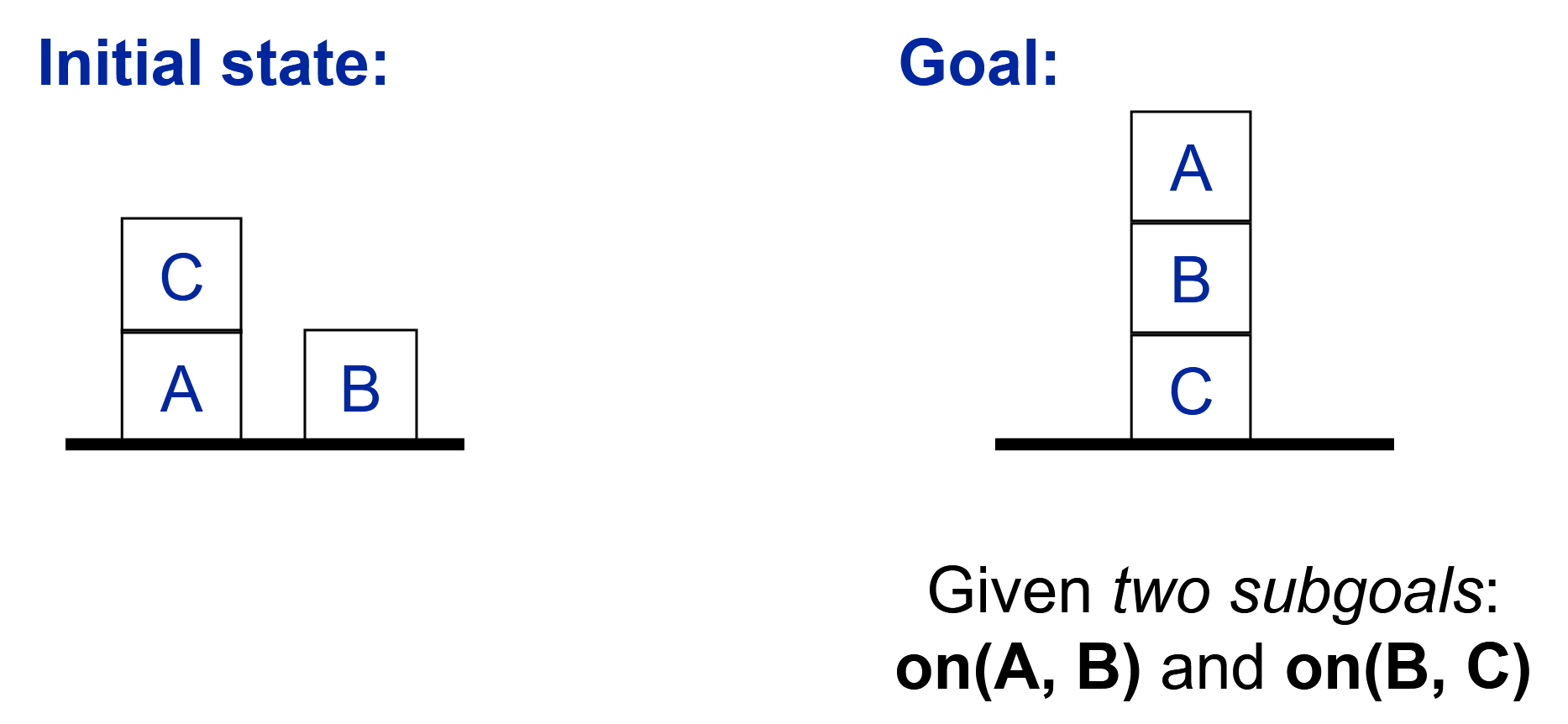
非交叉规划器当给定两个子目标
Initial State: on(C,A), clear(C), on-table(A), on-table(B),clear(B)
Goal: on(A,B), on(B,C),clear(A)
顺序 1:G1 → G2
1 | |
顺序 2:G2 → G1
1 | |
基于状态空间搜索的规划
规划即状态空间搜索
- 节点:世界状态
- 弧:动作
- 解:从初始状态到满足目标状态的路径
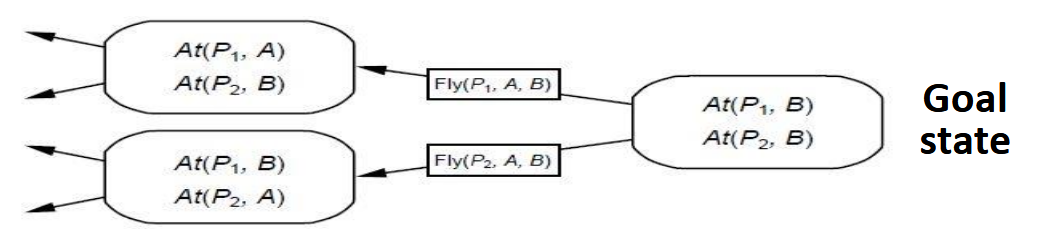
Progression(前向规划): forward search
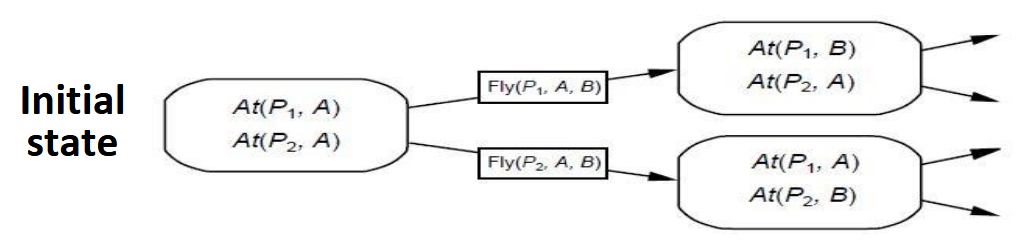
Regression(后向规划): backward search
偏序规划
生成偏序规划
- 节点为局部规划
- 连接表示规划细化
- 解为节点(非路径)
遵循最少承诺原则:除非必要,否则不对行动顺序做出承诺
Plan = (A, O, L),其中
- A:计划中的动作集合
- O:动作间的时序关系(例如 A1 < A2)
- L:通过文字项连接动作的因果连接
因果连接:
消费者行为

因果连接的威胁与保护
步骤
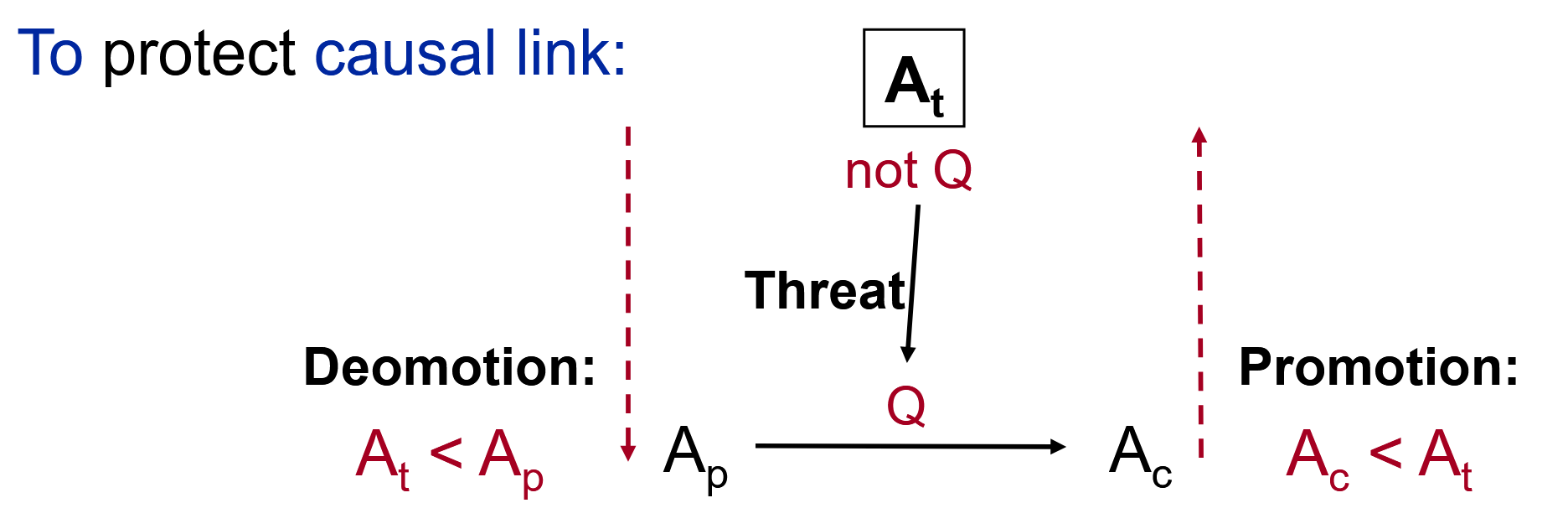
Initial Plan
为保持统一性,请使用两个特殊动作表示初始状态与目标:
Start(A0):
- 无先决条件,
- 初始状态即效果,
- 必须是规划中的第一步。
Finish(A∞):
- 无附加效果
- 目标作为前提条件
- 必须是规划中的最后一步
议程:开放条件集
例如:{(on(A,B),A∞), (on(B,C), A∞)}
Consistent Plan in POP
当且仅当:
- 排序约束中不存在循环,且
- 与因果连接无冲突
一个没有开放前置条件的
算法流程
POP((A, O, L), agenda, actions)
Initial plan: {Start, Finish} 且将
结束条件:如果
agenda 为空,则返回 (A,O,L) 确定
(子) 目标:从 agenda 中选择 (Q,Aneed),意思是 Aneed 需要前置条件 Q 选择动作:选择一个会产生效果
Q 的动作 Aadd - 如果不存在这样的动作,则失败
- 把因果连接
加入 L,把时序 Aadd < Aneed 加入 O - 扩展规划:如果
Aadd 是新动作,则把它加入到 A 中
更新
(子) 目标:把 (Q,Aneed) 从 agenda 中移除。如果 Aadd 是新动作,则对于它的每个前置条件 P,把 (P,Aadd) 加入到 agenda 中 保护因果连接:对于
A 中的每个会威胁 L 中的任意因果连接 Ap → Ac 的动作 At - 选择把
At < Ap 或者 Ac < At 加入到 O 中 - 若两项选择均不能满足一致性,则判定为失败
- 选择把
POP((A, O, L), agenda, actions)
图规划
主要思想
搜索算法中低效的一大根源在于分支因子,即每个节点的子节点数量
GraphPlan
- 创建松弛问题
- 移除原问题的部分限制条件,使松弛问题易于求解(多项式时间)
- 松弛问题的解将包含原问题的所有解
- 对原问题进行改进的搜索
- 将搜索空间限制在仅包含松弛问题解中出现的动作
GraphPlan [Blum and Furst 97]
- 在开始搜索前进行预处理
- 构建规划图以记录可能规划上的约束
- 结合前向扩展与后向搜索,包含两个阶段:
- 扩展:在每个时间步扩展规划图
- 搜索:利用规划图约束搜索以寻找可行解
- Graphplan 要么找到一个有效规划,要么得出无解的结论
图规划过程:
令 k = 0, 1, 2, … <规划图扩展>:
- 构建包含 k 个层级的规划图
- 检验规划图是否满足解存在的必要条件
- 若满足,则
<规划解提取>:
- 进行反向搜索,并限定仅考虑规划图中包含的动作
- 若找到解,则返回该解
规划图
该结构由一系列与规划时间步骤对应的层级组成,其中第
0 层为初始状态。 每个层级包含一组命题文字和一组动作,并通过边连接动作的前提条件与效果。
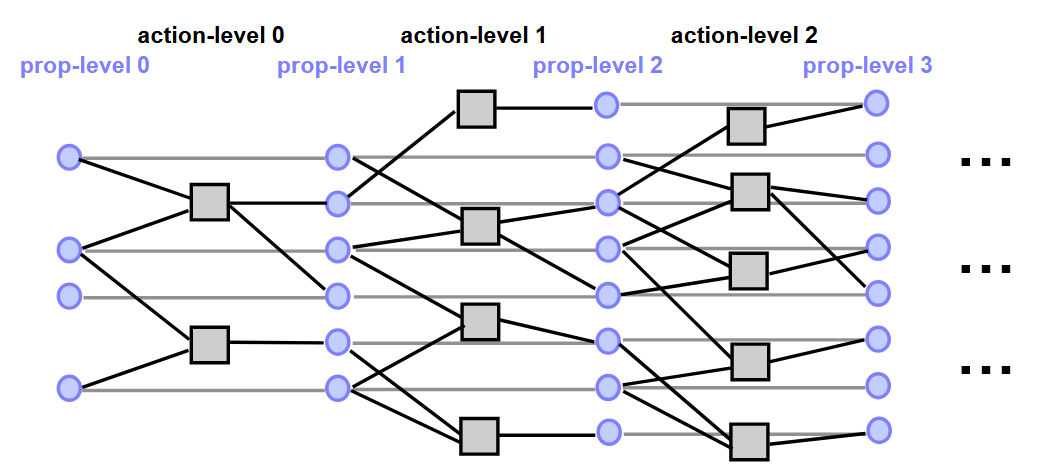
扩展图
Actions:
- 为扩展第
i 层动作: - 添加所有实例化的动作,其全部前提条件均存在于第
i 层命题中,且任意两个前提条件互不排斥 - 添加所有空操作
- 添加所有实例化的动作,其全部前提条件均存在于第
- 确定互斥动作
Propositions:
- 拓展命题层级 i+1:
- 在动作层级 i 中,添加所有插入动作的效果:需区分增加效果与删除效果。
- 确定互斥命题
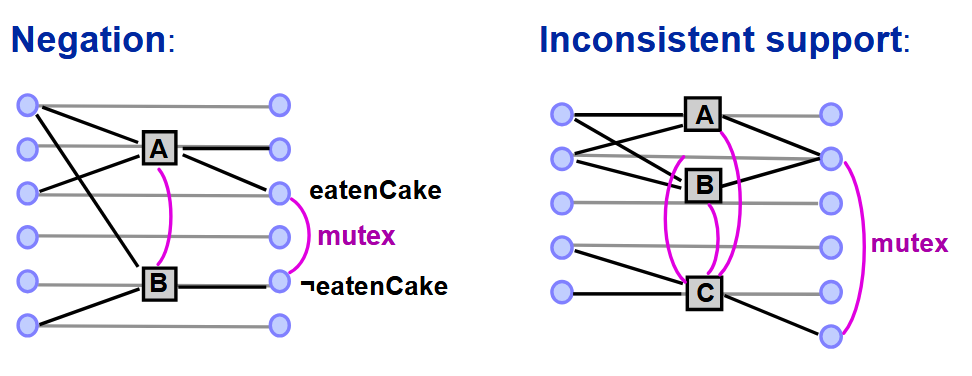
Mutex Relations:
若满足以下任一条件,则动作
- 干扰
(Interference):A(或 B)会解除 B(或 A)的前提条件或效果 - 需求竞争
(Competing needs):A 与 B 具有互斥的前提条件
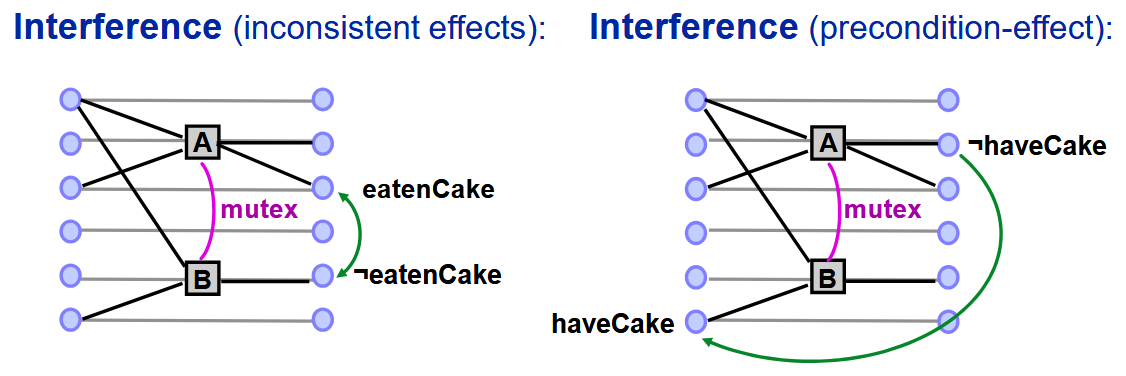
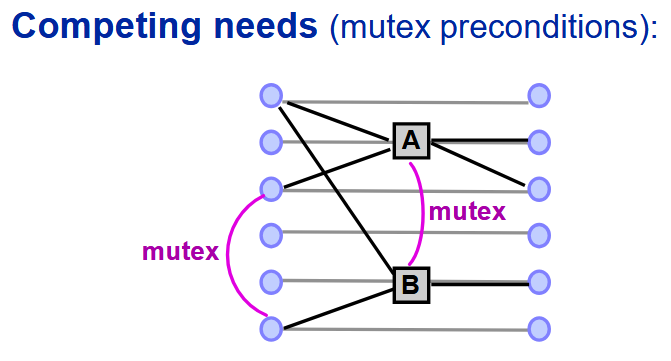
若满足以下任一条件,则两个命题
- 否定关系
(Negation):p(或 q)是 q(或 p)的否定 - 不一致支持
(Inconsistent support):所有实现它们的方式互斥(即所有添加 p 的动作与所有添加 q 的动作相互排斥)
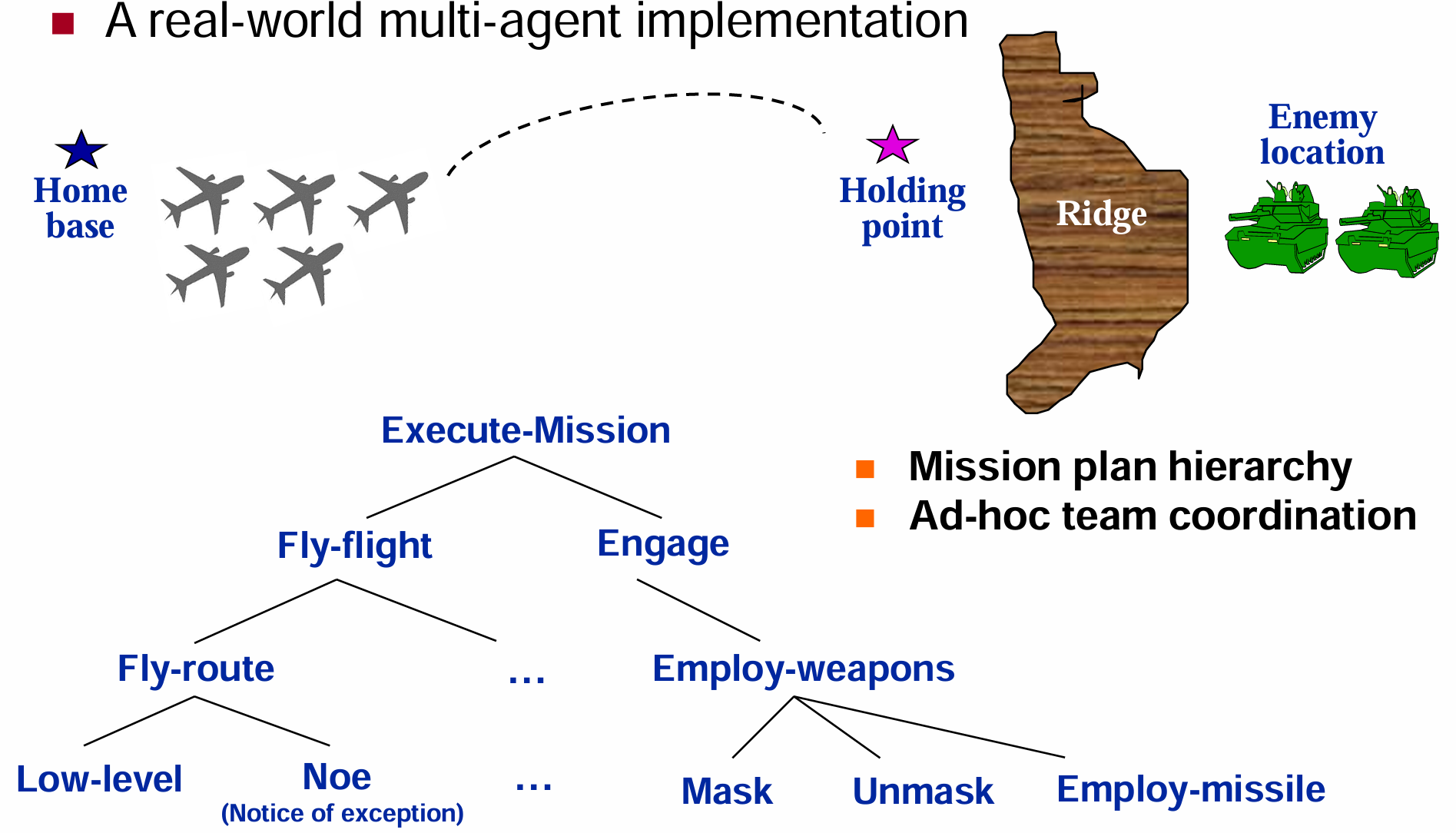
团队合作
理解团队合作 (Understanding Teamwork)
- 团队合作的本质:团队合作不仅仅是多个成员同时采取协调一致的行动(例如普通交通或车队行驶),而是团队成员为了实现共同目标而进行的合作努力 。
- 为什么需要团队:组织团队可以建立更健壮的结构,成员可以在遇到困难时互相帮助,互相替代履行责任,并确保关键信息传达给队友 。团队中不同的角色可以承担不同的责任,弥补个体能力的局限 。
- 构建团队的难点:在复杂的环境中,成员动态获取的信息往往是不完整的,沟通不仅耗时、成本高而且存在风险,此外团队成员还可能发生意外失败(如无人机坠毁) 。
- “特设(Ad
Hoc)”
协调的局限性:在小规模团队中,依靠预先固定的协调规划可能有效,但这缺乏应对失败的框架,会导致系统缺乏灵活性且难以复用 。在大型复杂场景中,这种方式会导致严重的团队混乱(例如侦察兵坠毁后整个队伍陷入无限等待) 。因此,需要基础的团队合作理论作为支撑 。
团队合作理论 (Teamwork Theories)
理论的目的是为了从根本上理解团队合作,并为构建健壮的团队应用程序提供规范 。
联合意图理论(Joint Intentions)


- 承诺(Commitment)是团队合作的核心,理论关注的是
“团队承诺” 而非个体承诺 。 - 共同的信念(Mutual Belief, MB):指成员之间关于某事的无限层级嵌套信念(“我相信你相信我相信……”) 。
- 联合持续的目标(Joint Persistent Goal, JPG):这是定义团队承诺的核心概念。它要求团队共同相信目标尚未达成,并拥有实现该目标的共同目标 。
- 弱目标(Weak Goal,
WG)与沟通:直到团队共同相信目标已达成、永远无法达成或无关紧要之前,成员必须保持
“弱的共同目标” 。这意味着,如果某个成员私下发现目标无法实现,他不能直接放弃目标走开,而是必须承担向队友通报的责任,直到使这一情况成为全队的 “共同信念” 。这就为团队合作中的 “沟通” 提供了坚实的逻辑依据 。
共享规划(Shared Plans)
与联合意图不同,它不依赖于联合的心理状态,而是强调成员为了团队目标展现出合作行为的
实用的团队合作模型 (STEAM)
STEAM
- 层次化规划与组织结构:STEAM
使用了层次化的 “响应式团队规划”(包含执行前提、执行体和终止条件) 。同时,它还定义了包含团队、子团队、个体的组织架构,并将特定的角色分配给这些层级 。 - 执行与监控:在运行时,每个智能体都在本地维护一份团队程序的副本
。所有团队规划的执行和终止都通过建立
“联合承诺” 来完成 。 - 故障修复(Monitor and
Repair):如果团队中某个成员失败(例如侦察角色未完成),STEAM
会评估角色依赖性(如 AND/OR 约束) 。如果发生关键故障,团队会通过能力匹配重新分配角色,能力最强的候选者将接替任务 。 - 选择性沟通(Communication
Selectivity):为了降低沟通成本,STEAM
引入了决策理论模型。它会计算 “沟通的预期效用(EU(Comm))” 和 “不沟通的预期效用(EU(No Comm))”,只有当沟通带来的团队收益大于沟通成本时,智能体才会发送信息 。